【同样是抢实体数据,为什么百度文心不用拆书?】
现在AI的竞争赛道已经开始变了,全网公开数据已经挖不出新东西,所有人都盯着实体纸质数据这块大蛋糕。但有意思的是,同样是抢数据,别家AI砸钱拆书、费力人工录入,百度却全程轻松拿捏,差距到底在哪?答案很简单:OCR技术根本不在一个层级。
说实话,现在能让大模型突破能力上限的,只剩下海量实体书、古籍、老档案这些未开发的优质数据。为了抢占这份资源,Anthropic和GPT之父的操作,看着热闹,实则全是笨办法,也暴露了传统AI的致命缺陷。
Anthropic的方式堪称“暴力采集”,花大价钱收书,拆书扫描、用完销毁,早年还靠盗版电子书补数据,不仅成本高、浪费资源,还一直陷在版权争议里。归根结底,就是传统OCR太弱,识别不了不平整、不标准的纸质书页,只能费劲改造现实场景去适配机器。
GPT之父的操作也不轻松,为了训练Talkie模型,硬生生手动OCR录入了海量百年前的旧文献、专利文书和法律判例。全程耗时又耗力,但也侧面证明了实体数据的含金量,同时凸显了行业的通病:没有高效智能的识别技术,只能靠人力硬堆。
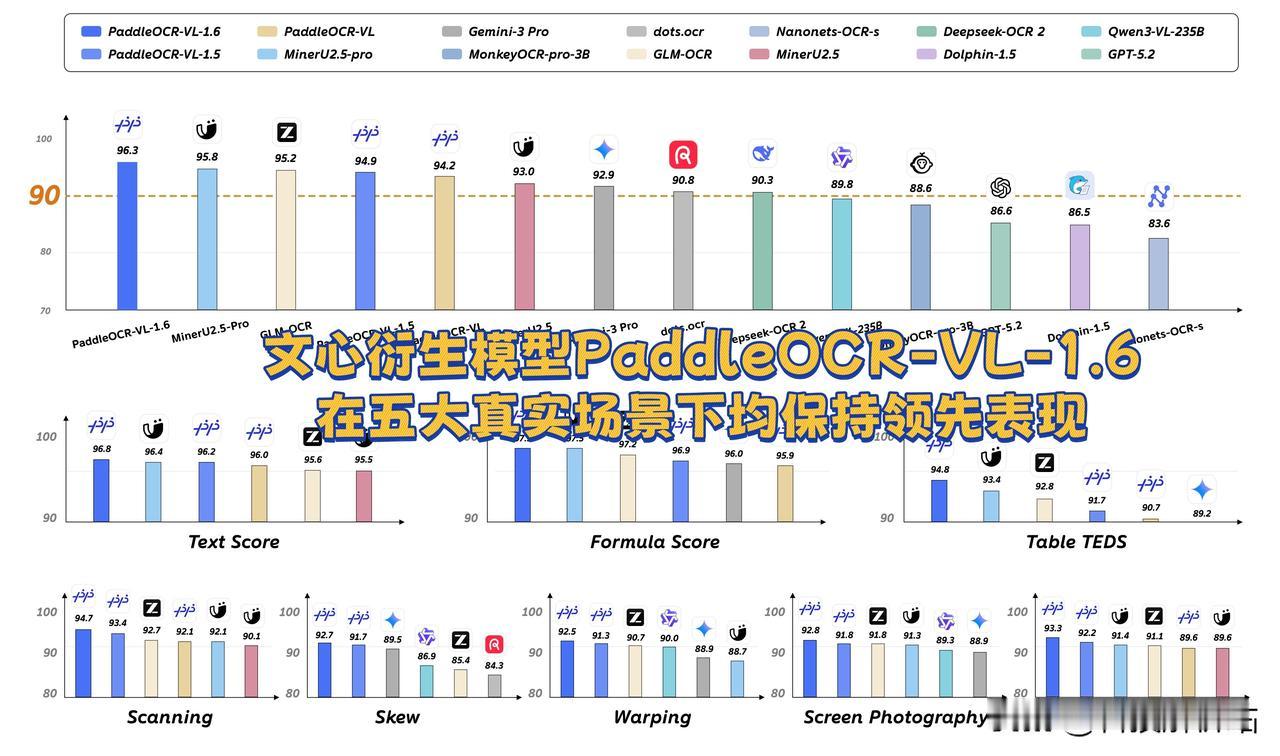
当同行还在靠人力、物力死磕数据采集时,百度文心已经实现了降维打击。全新发布的PaddleOCR-VL-1.6,是基于文心大模型迭代升级的多模态核心模型,优势特别亮眼,仅0.9B超轻量参数,体型小巧、推理速度快,部署落地门槛极低,普通设备也能轻松跑通,真正做到了小模型、超能力,整体实力完全越级碾压一众大参数竞品。在业内权威的OmniDocBench v1.6榜单评测中,它拿下96.33%的超高准确率,综合性能稳居全球第一。
它最核心的突破,就是彻底告别了“改造世界适配AI”的落后逻辑。不管是皱巴巴的古籍、角度随意的实拍文档,还是排版混乱的老报刊、光线不均的纸质资料,都能一键精准识别、深度解析。不用人工干预,不用破坏实体书籍,就能盘活所有沉睡的优质数据。
这就是AI行业的真实差距:低端玩家消耗资源迁就技术,高端玩家靠技术适配全局。PaddleOCR的强势出圈,既印证了文心大模型的硬核实力,也坐实了一个新趋势:OCR就是AI通往现实世界的核心数据入口,掌握了顶尖OCR技术,就掌握了未来AI迭代的话语权。
百度 文心 文心5 文心大模型 paddleocr 谷歌 OCR DeepSeek AI大模型