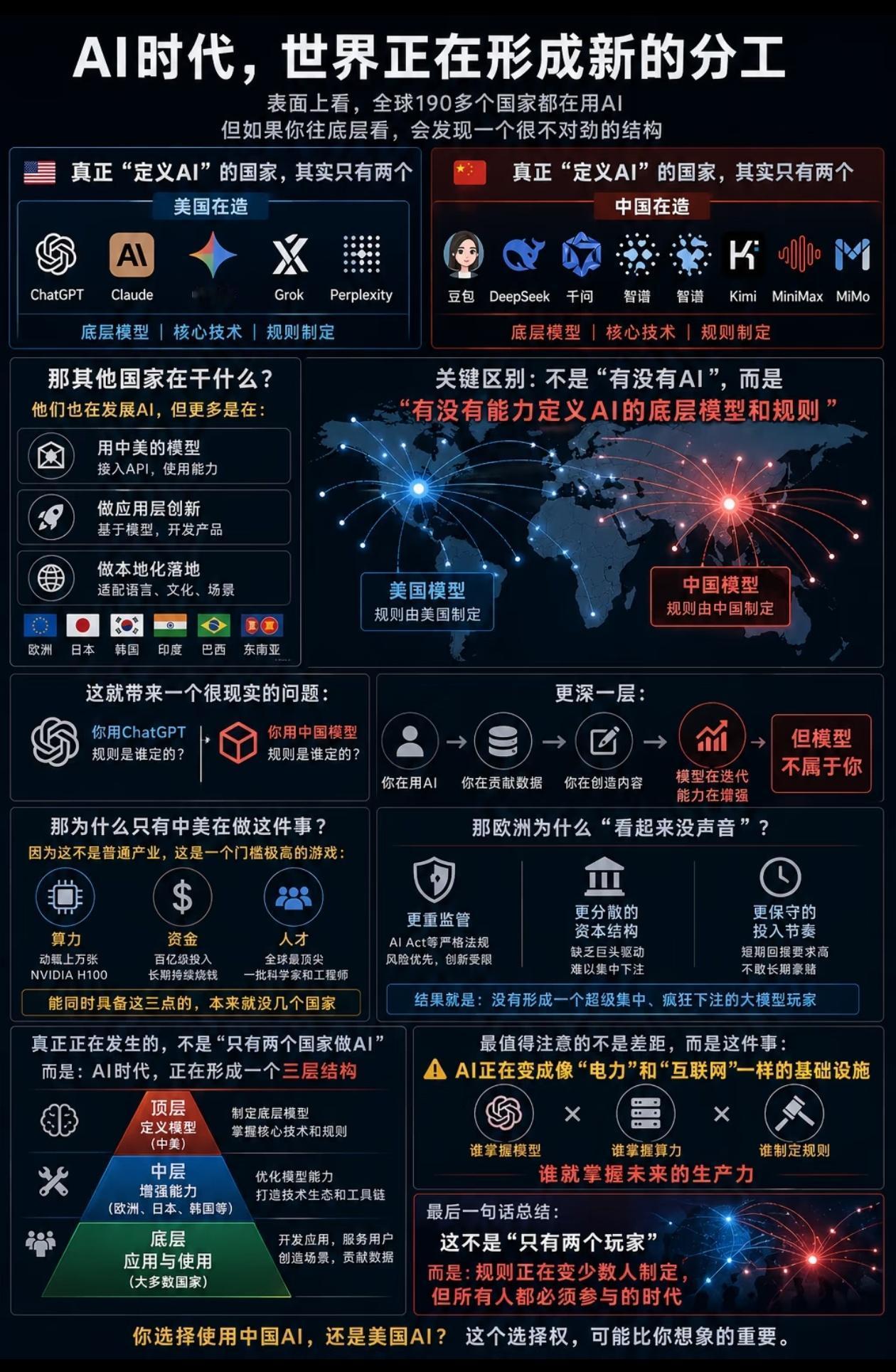
很多人想不通,为何AI盛世只有中美对垒,德法日韩却颗粒无收?这无关技术高低,而是他们丢了入场券。
最近有个数据在圈子里传得挺猛:全球AI大模型一周的调用量,加起来差不多到了9.8万亿token。
数字听着有点抽象,但换个角度看就很直观,榜单上前十个模型,刚好一半来自中国(基本集中在北京、深圳),另一半来自美国硅谷。
有意思的是,名单里完全看不到别的熟面孔,像慕尼黑、巴黎、东京、首尔这些传统科技强区,这次直接缺席。不是排在后面,是压根没上桌。
这件事让人多少有点意外,毕竟这些国家在过去的AI研究里并不弱,论文、算法、实验室成果都挺能打。但到了大模型这一轮,感觉像突然换了赛道,原来的优势一下子没那么好用了。
现在拼的东西,其实有点“粗暴”:算力、数据,还有钱,这三样东西缺哪一个,都很难往前走。
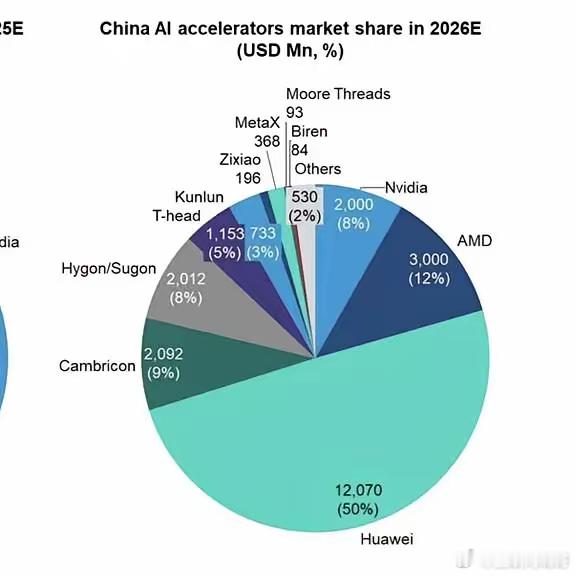
先说算力。像英伟达的H100这种显卡,现在已经不太像普通商品了,更像是关键资源,美国这边掌握着芯片设计和供应链的一部分,中国这边则在拼命铺算力基础设施,数据中心一片一片地建。
关键还有一个常被忽略的点,电价。
训练一个大模型,耗电量是非常夸张的,中国西部很多地方水电、风电资源充足,电价相对低,像内蒙古、贵州、云南这些地方,数据中心越建越多,说白了就是“电便宜,敢开机器”。
反过来看欧洲,能源这几年一直紧张,电价高得离谱。企业不是不会算账,训练一次模型可能就是一笔巨额电费,很多项目从一开始就卡住了。不是技术做不到,是成本顶不住。
再往下看数据这一块。
大模型本质上是“吃数据长大”的,数据越多、越丰富,模型能力才容易提升。英语在全球互联网里的占比太大了,美国天然占优势;中文这边靠着庞大的用户规模,也能形成自己的数据池。
但像德语、法语、日语、韩语这些语言,用户规模和内容总量都有限,很难支撑一个面向全球的大模型持续训练。
举个例子,法国那家AI公司Mistral,技术其实不差,但更多是在做开源小模型。原因也很现实,做大模型太烧钱,靠本地市场很难回本,闭源路线压力太大。
更微妙的是,很多德法日韩的用户,其实已经在用中美的大模型产品了,使用习惯一旦形成,本土公司就算后来推出类似产品,也很难再把用户拉回来。
最后一个因素是资本。
大模型这件事,本质上是长期投入、短期看不到回报的那种项目。美国的风投体系,对这种高风险高投入的项目接受度比较高;中国这边,则有政策和产业层面的支持,愿意持续砸资源。
欧洲企业很多时候更看重短期财务表现,投入这么大一笔钱,回报周期又长,内部决策就会变得很谨慎。
日本、韩国的大公司虽然资金雄厚,但更倾向投那些确定性更高的领域,比如半导体设备、制造业升级这些。
所以你会看到一个有点反差的情况:在2010年代,像东京大学、KAIST,还有德国的科研机构,在AI论文和基础研究上都挺活跃的。
但到了大模型阶段,规则变了,从“谁算法更巧妙”变成“谁资源更充足”。
这种变化不是一两年能补上的。
当然,也不能说德法日韩完全没机会。他们在一些垂直领域,比如工业控制、精密制造、医疗影像,依然很有优势。这些领域对数据和模型规模的要求不完全一样,更看重行业经验和积累。
只是整体来看,位置确实有点变化,从以前某种程度上的“规则参与者”,变成更多在特定场景里发力的角色。
同时,中美这两边还在继续加码,算力更大、模型更复杂、投入更多,门槛被一层层抬高,后来者想追上,就不只是技术问题了,还涉及整个体系的投入能力。
所以现在这个榜单上的“空白”,短时间内大概率不会轻易被填上。不是谁突然慢了一步,而是这场游戏本身,已经变成另一种玩法了。