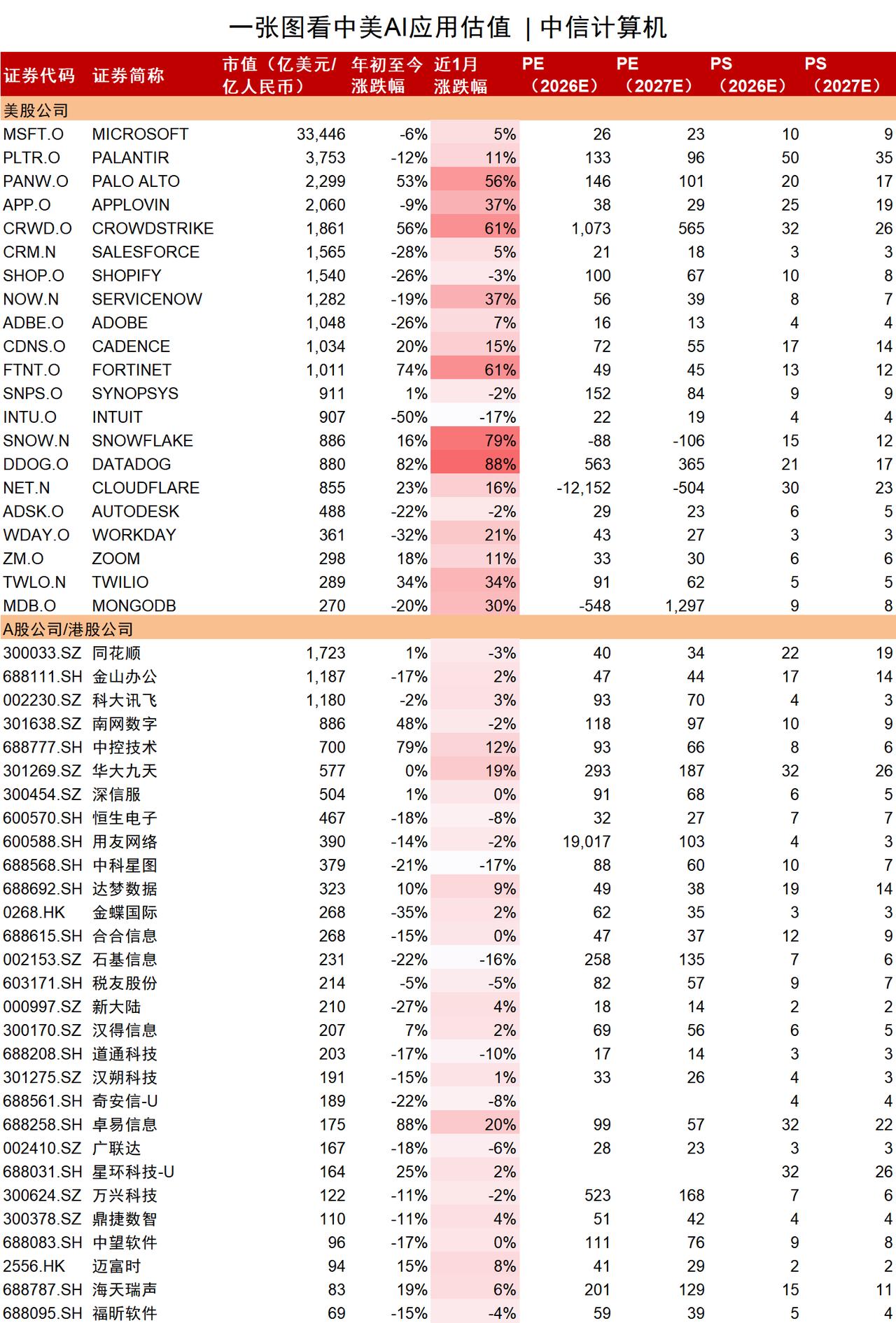
这是 DeepSWE Benchmark 2026年6月更新的AI编程能力榜单,衡量的是模型在长程工程任务中的完成率,是目前最能反映真实编程能力的权威测试之一。
🏆 核心排名与解读
1. GPT-5.5 以70%登顶
OpenAI 依然领跑,GPT-5.5 以70%的完成率大幅领先,在复杂工程任务中展现了极强的问题拆解与代码实现能力。
2. Claude Opus 4.8 杀回第二,以58%紧随其后
最新的 Opus 4.8 版本大幅提升了编程能力,以58%的成绩超越了 GPT-5.4(56%),展现了Anthropic在工程领域的追赶势头。
- 对比前代:Opus 4.7为54%,Opus 4.6为28%,版本迭代带来了质的飞跃。
3. 梯队差距明显
- 第一梯队(≥50%):GPT-5.5、Claude Opus 4.8、GPT-5.4,这三款模型在长程工程任务中表现出显著优势。
- 第二梯队(20%-40%):Claude Opus 4.7、Claude Sonnet 4.6、Gemini 3.5 Flash 等,能应对常规开发任务,但复杂场景仍有差距。
- 第三梯队(<20%):国内模型与部分开源模型,在复杂工程任务中仍有较大提升空间。
💡 关键结论
- OpenAI 领跑,Claude 猛追:榜单清晰展现了两大巨头的竞争格局,GPT-5.5 仍是绝对王者,但 Claude Opus 4.8 的进步速度惊人。
- 模型版本迭代效果显著:同系列模型的不同版本之间差距巨大,Opus 4.8 相比 4.6 实现了翻倍的提升,说明最新模型才是真正的生产力工具。
- 工程能力≠日常编码:该榜单测试的是长程、复杂工程任务,和日常写小脚本、查bug的场景不同,所以你在IDE里用 Cursor/Claude Code 时,体感可能和榜单不完全一致。
一句话总结:如果你需要处理复杂项目重构、大型Bug修复等硬核工程任务,GPT-5.5 仍是首选;但 Opus 4.8 已经成为极具竞争力的第二选择,在很多场景下可以作为 OpenAI 的替代方案。
ai价值榜 ai调研报告 AI测评体系 AI能力分级 AI模型横评 AI底层架构 AI编程平台