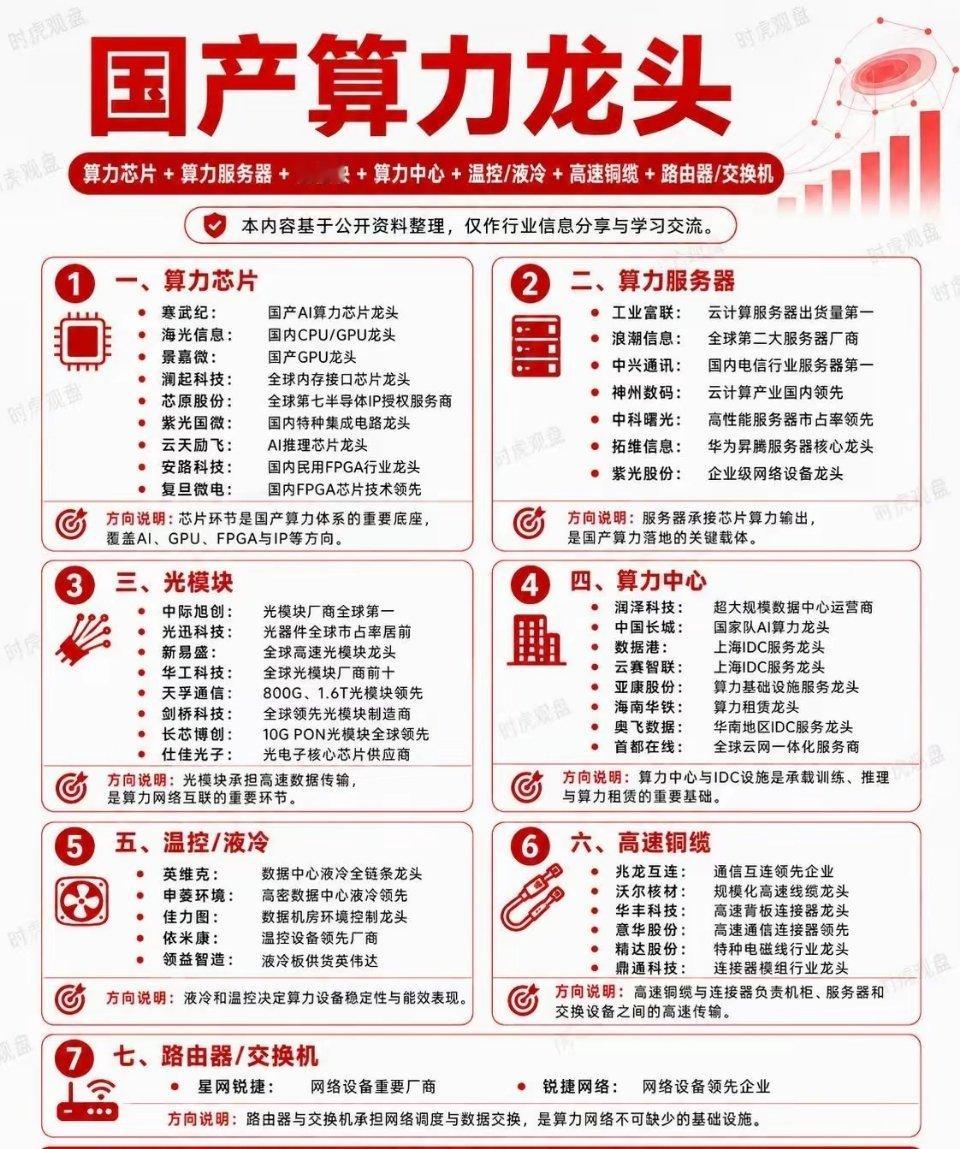
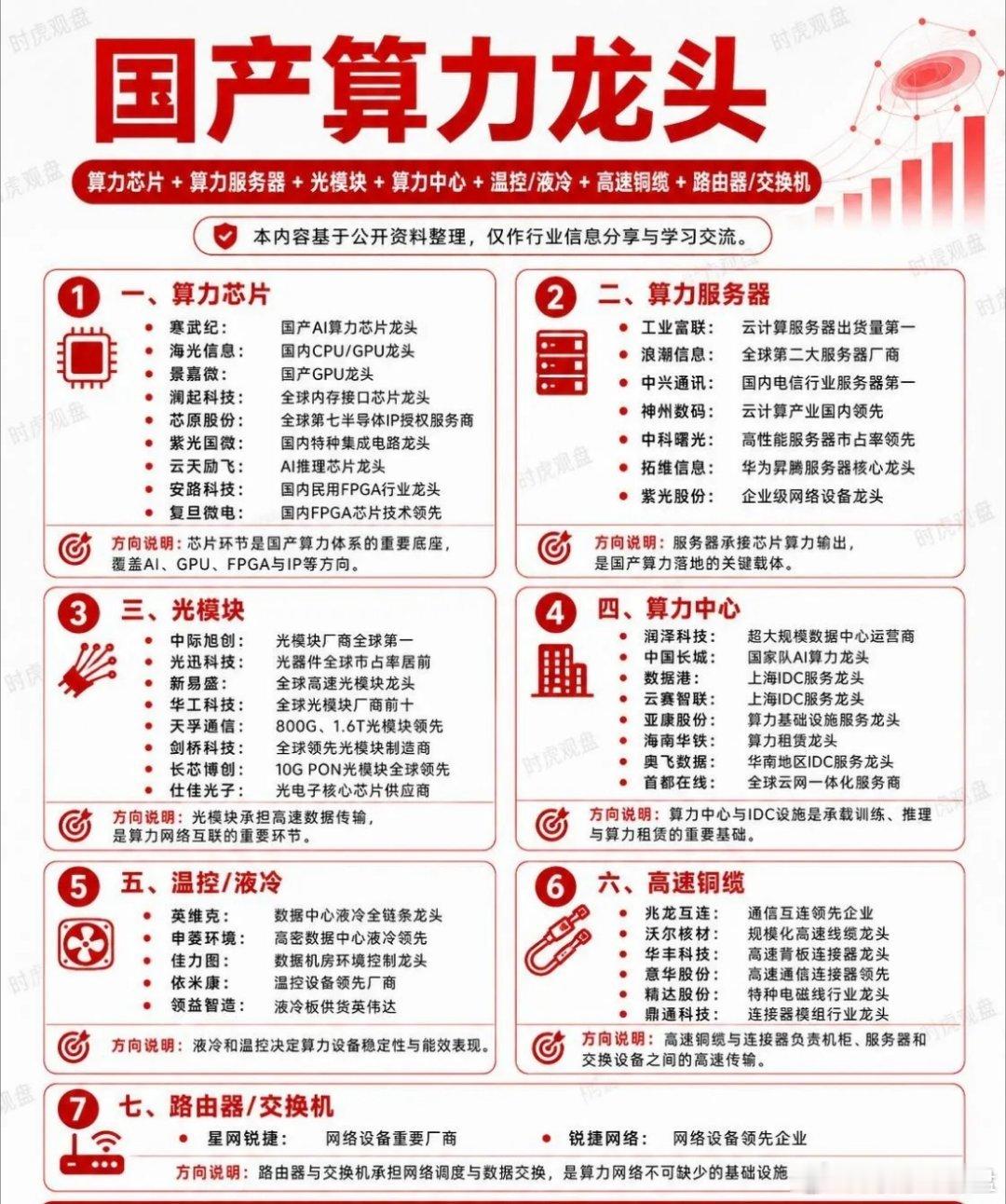
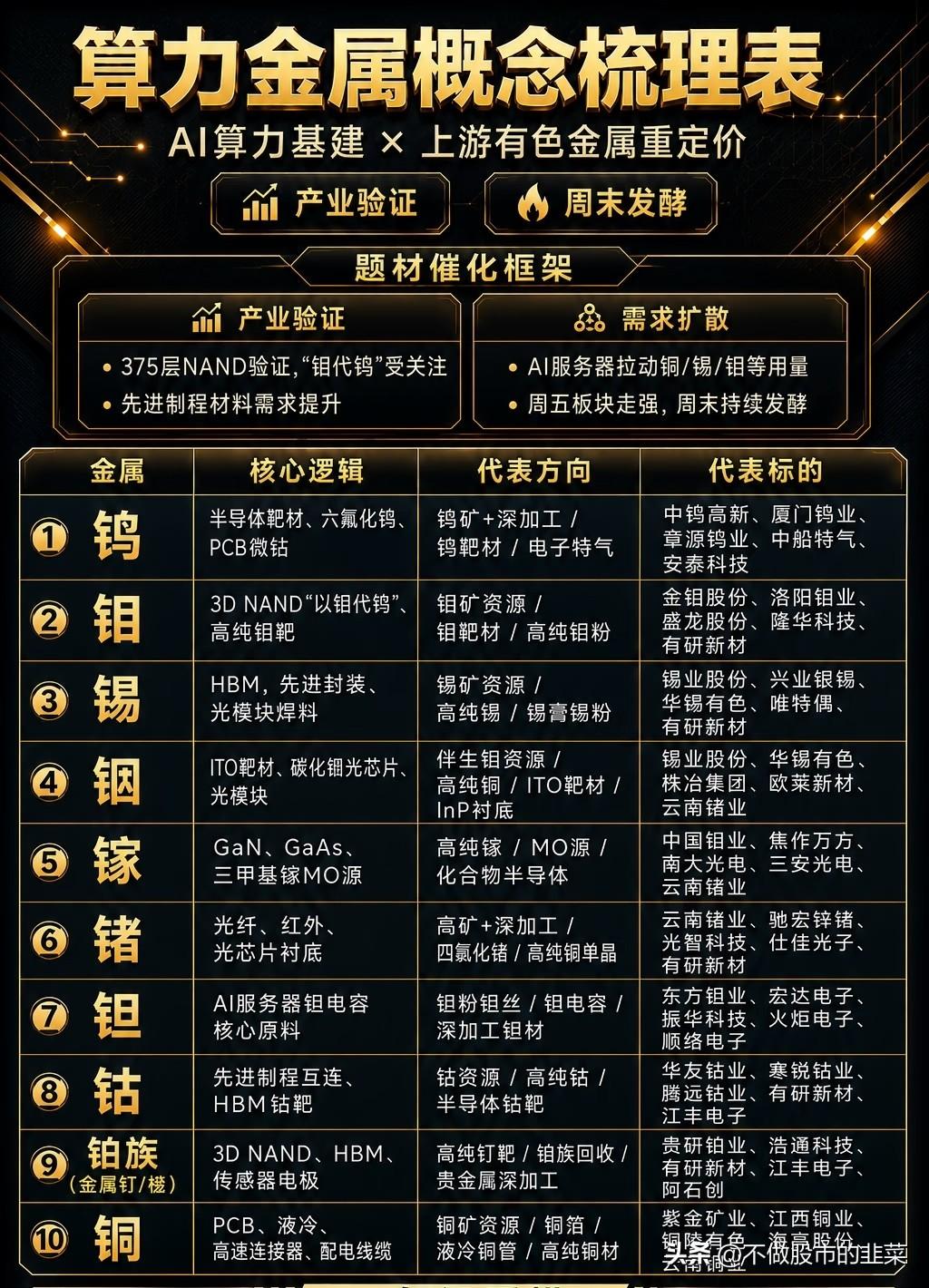
标签: GPU








科技股迎来新的赛道,下半场的主线或许就是CPUAI炒作时代(堆GPU)结束,实
科技股迎来新的赛道,下半场的主线或许就是CPUAI炒作时代(堆GPU)结束,实用落地时代(CPU+各类端侧芯片)开启,国产CPU迎来AI行业的增量红利。AI时代已经告别单纯比拼显卡数量、堆超大算力集群的内卷阶段,行业重心转向赚钱、落地商用,行业估值逻辑重塑:不再只看GPU供货量,CPU、端侧专用芯片、行业推理方案都具备长期增长逻辑。十万卡全国产集群接入国家超算互联网,是数字基础设施自主可控标志性工程。大规模AI产业不再受制海外芯片供给限制,国家层面算力安全、数据安全保障能力提升,后续政企AI项目会优先采用国产CPU整机。单纯GPU炒作降温,国产服务器CPU、嵌入式芯片、边缘推理硬件成为新主线;市场重新定价海光等国产CPU企业:市场之前只把它当作普通服务器芯片厂商,现在确认深度绑定AI下半场刚需,业绩增长预期上调;端侧推理、行业AI应用、向量数据库配套硬件迎来估值修复机会。





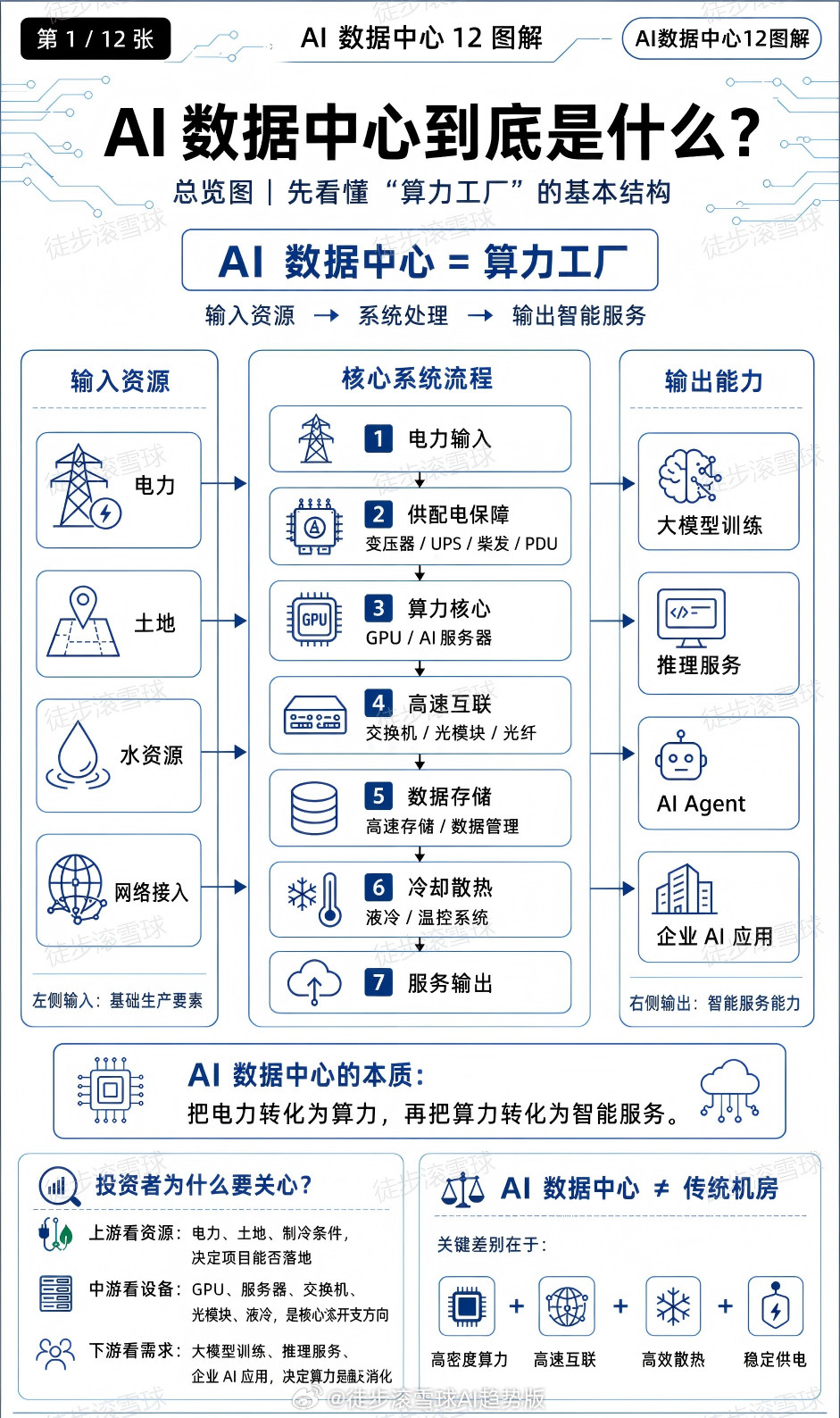
红利AI基金etf12张图读懂AI数据中心:从电力到算力,从硬件到应用AI数
红利AI基金etf12张图读懂AI数据中心:从电力到算力,从硬件到应用AI数据中心不是机房,而是Token工厂。AI数据中心的本质,不只是把电力转化为算力,而是把算力进一步转化为Token、API调用和企业生产力。最近两年,AI产业链越炒越细:从大模型到算力,从GPU到光模块,从液冷到电力设备,再到PCB、变压器、储能和数据中心。很多人的问题不是“不关注AI”,而是越看越乱:到底什么是真需求?什么是蹭概念?AI数据中心为什么会同时拉动这么多行业?所以我整理了这组图,想用更直观的方式,把AI数据中心这件事讲清楚。看懂这个框架,才知道为什么电力、GPU、光模块、液冷、PCB、存储都会被卷进来;也才能分清楚,哪些环节是真正的核心瓶颈,哪些只是普通配套,哪些又可能只是短期概念炒作。$半导体ETF国联安sh512480$$兆易创新sh603986$$寒武纪sh688256$





【华为Mate80Pro性能解禁:麒麟9030ProGPU相比
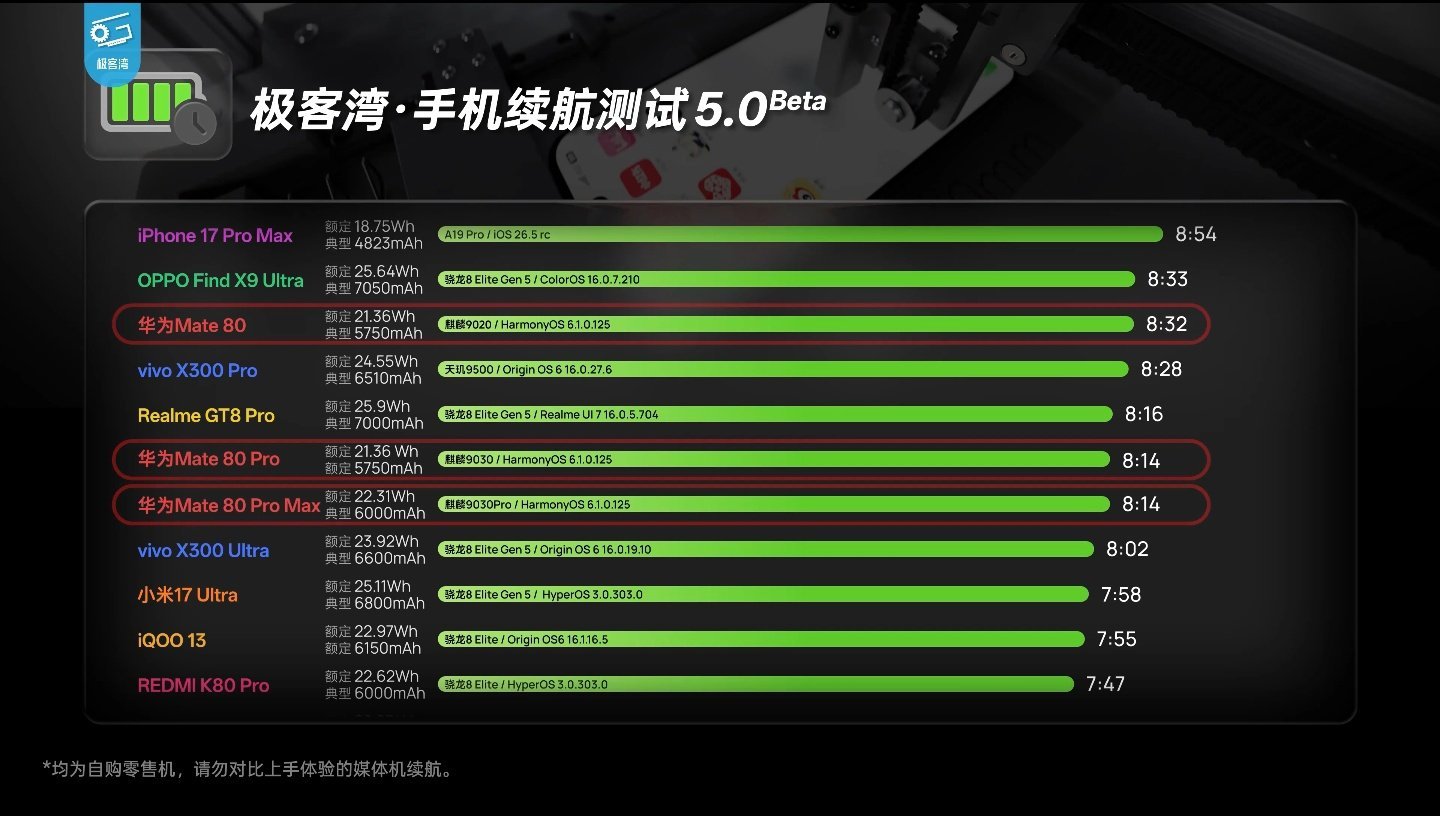
【华为Mate80Pro性能解禁:麒麟9030ProGPU相比9020提升76%,《原神》能效表现优于高通骁龙8Gen3】华为去年发布了Mate80系列旗舰手机,搭载华为自研的麒麟9030及麒麟9030Pro处理器。今日,B站up主放出了一期针对华为Mate80Pro的性能分析报告。据介绍,这两款芯片均基于同一种Die,估算约有150亿晶体管,规模与苹果A15、高通骁龙8Gen2接近。其中,满血版的麒麟9030Pro采用9核14线程架构,包含一颗2.75GHz超大核、四颗2.27GHz大核及四颗1.72GHz小核,并集成6核马良935图形处理器。麒麟9030则在此基础上屏蔽一颗CPU大核变为8核12线程,并采用了5核马良935AGPU。架构方面,麒麟这代大核与小核变化不大,主要对超大核寄存器深度及乱序执行窗口进行了微调。缓存上,超大核L2缓存翻倍至2M,5颗大核共享的L3从10M升级到12M,SLC缓存也提升至12M。在能效测试中,极客湾移植了原生的SPECCPU2017测试,并结合HiSmartPerf高性能模式进行了测试。结果显示,麒麟9030Pro的超大核能效稳步提升,性能接近高通骁龙8+的Cortex-X2核心,虽然仍未超越X2,但差距已非常接近。另外,麒麟9030Pro浮点性能进步更为明显,中频段能效表现出色。多核能效方面,得益于工艺升级和核心数量增加,9030Pro的多核能效曲线落在骁龙8Gen2和8Gen3之间,中低频能效甚至接近8Gen3,相比前代9020提升巨大。GPU方面,马良935架构获得了显著提升,ALU单元相比前代翻倍,算力提升超过200%。在3DMark的SteelNomadLight测试中,9030Pro比9020强了76%,能效曲线与骁龙8+接近。此外,9030Pro的NPU升级为“一大两小”三NPU架构,ISP方案也升级至9.0,基带面积则大幅缩减了31%。在实际应用表现方面,鸿蒙原生版《原神》的表现令人惊艳。Mate80ProMax在804P分辨率下可实现全程60帧畅玩,整机功耗仅4.9W,能效甚至优于8Gen3在720P下的表现。这得益于鸿蒙原生应用去除了冗余代码,以及芯片底层对图形驱动的深度优化。在《王者荣耀》120fps极致设定下,其平均功耗仅3W,能效表现极其出色。对于《异环》等游戏,虽然目前调度策略尚有优化空间,但整体表现已处于行业第一梯队。针对光线追踪技术,麒麟9030Pro集成的马良935GPU首次支持该功能,在《暗区突围》等重载场景下,系统通过针对性的驱动层优化,实现了功耗控制与性能释放的平衡。极客湾指出,Mate80系列的系统流畅度也远超预期。鸿蒙系统配合麒麟9030芯片,通过更智能的调度策略,避免了安卓端常见的“一刀切”限频问题,加上原生应用的高效开发框架,使得交互体验异常顺滑。华为Mate80Pro配备5750mAh电池,Mate80ProMax配备6000mAh大电池。测试数据显示,两款机型在极客湾5G续航5.0模型测试中均取得8.14分的成绩,在一众旗舰中稳稳保持第一梯队级表现。
















大半夜的,又一条消息把我看得睡意全无。不是开玩笑,业内迎来一次重大技术突破。国产
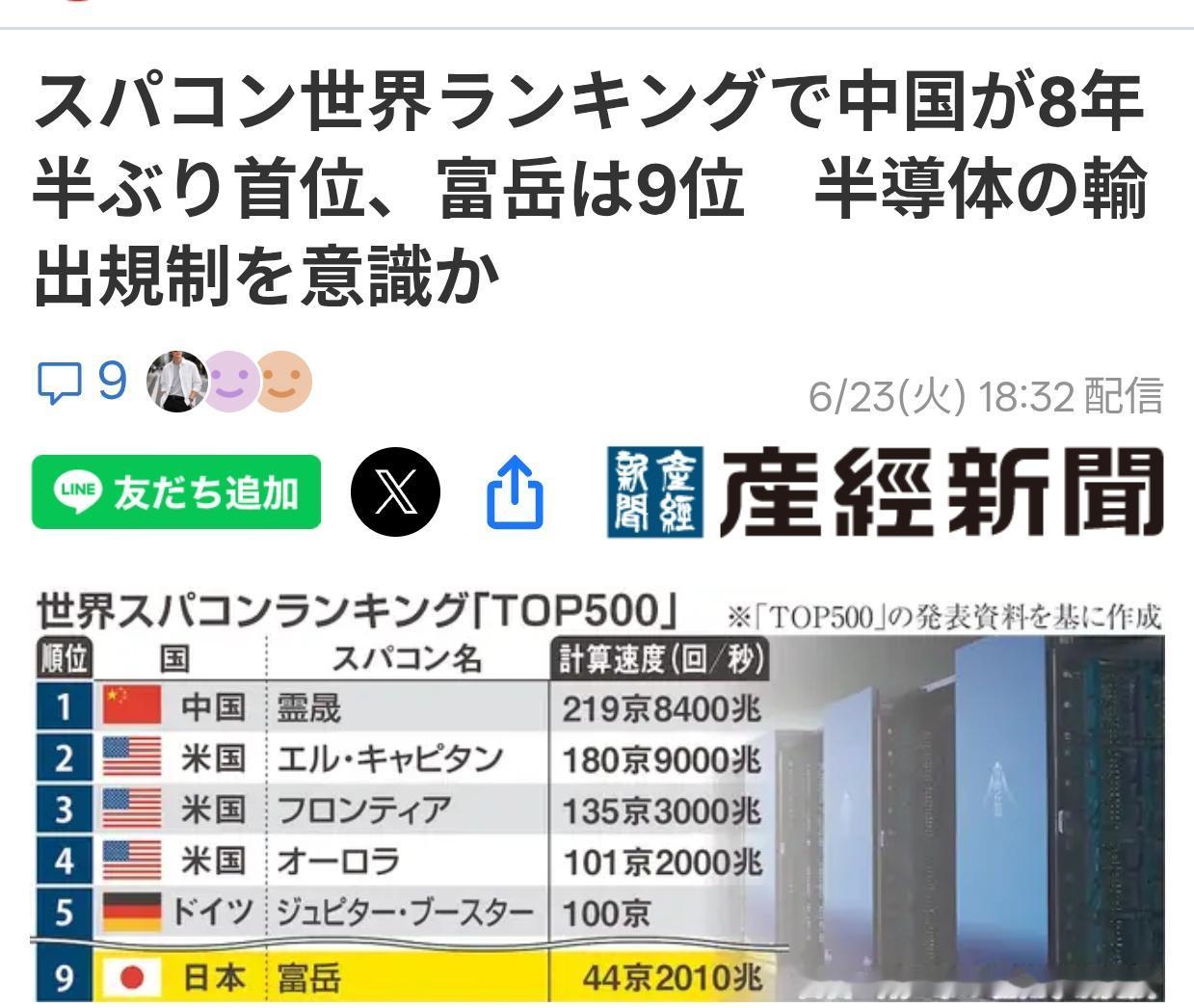
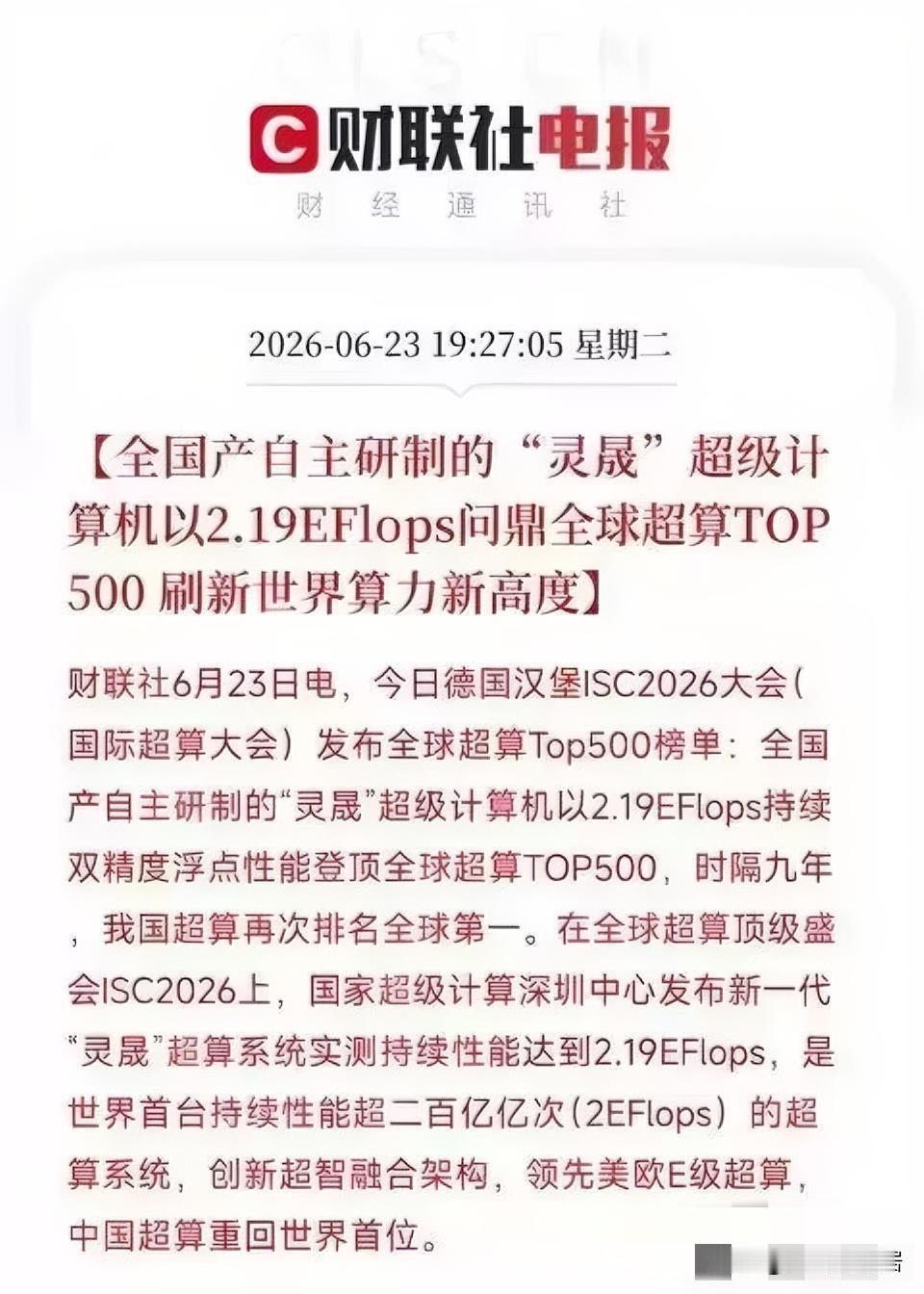
大半夜的,又一条消息把我看得睡意全无。不是开玩笑,业内迎来一次重大技术突破。国产超算灵晟实现全国产自主化,在德国汉堡举办的国际超算大会上,成功登顶全球超算TOP500榜单榜首。2.19EFlops是什么概念?也就是每秒二百亿亿次运算。打个通俗比方,就算全球几十亿人同时用计算器计算,耗费漫长时间,也难以追上它一秒钟的运算量。这台超算部署在深圳国家超算中心,完成了一次重磅突破。最亮眼的地方在于它走出了一条全新的技术路线。当前全球主流超算普遍采用CPU搭配GPU的异构方案,美国顶尖超算大多依靠英伟达、AMD加速芯片搭建。灵晟没有搭载任何GPU,仅凭自研国产CPU完成运算,走出了不一样的技术道路。多年来,高端半导体领域持续遭遇技术限制,反而倒逼我们打造出这台全国产化超算。从处理器、高速互联网络到操作系统,软硬件全部实现自主研发。技术封锁往往就是这样,越是严苛限制,越能激发自主研发潜力。该项目负责人为国家超算深圳中心主任卢宇彤,她在汉堡现场发言时提出:这是回归计算加速的本质。简单来讲,不再一味照搬国外既定技术路线,走出属于我们自己的研发道路。传统超算需要搭配GPU,是因为CPU处理人工智能任务效率有限。这台灵晟直接在国产CPU内部集成了AI加速单元,内存带宽相比传统CPU提升十倍。相当于自主研发核心硬件,摆脱对外来配件的依赖。不少人会疑问,跑分高是不是只做数据测试?其实不然。该设备已经投入大气海洋模拟、新药研发、脑科学等科研项目,大规模并行运行效率稳定保持在84%以上,兼顾运算性能与实际科研用途。上一次国产超算拿下全球榜首,是2017年的神威太湖之光,时隔整整九年再度重回第一。此前一直有舆论唱衰国内超算发展,科研团队潜心深耕,终于交出亮眼成绩。这条新闻带来的启发十分深刻:单纯依靠技术封锁,很难遏制一个国家尖端科技的发展。图灵奖得主唐加拉现场评价,这套超算体系,为超算结合人工智能科研开辟了全新方向,这份评价分量十足。看完这则消息不由得感慨,手握核心技术和单纯具备技术潜力完全是两回事。如今我们不仅拥有顶尖算力设备,还建成了完整的自主产业链。未来,这台超算还会持续助力人工智能与基础科学研究。信源:综合科技日报、央视新闻、观察者网等媒体2026年6月23日报道。

美团投资的AI独角兽公司一、通用大模型独角兽1. 智谱AI(清华系大模型龙头)
美团投资的AI独角兽公司一、通用大模型独角兽1.智谱AI(清华系大模型龙头)美团战略入股,持股约5.54%,投前估值200亿元,国内头部通用大模型2.月之暗面(Kimi母公司)美团A1轮领投,最新估值超200亿美元,长文本大模型标杆,Kimi为国民级AI工具。3.光年之外美团20.65亿元全资收购(王慧文创办),初创即达2亿美元估值,AGI技术团队并入美团自研大模型LongCat。二、具身智能/机器人独角兽1.宇树科技(Unitree)美团第一大外部股东(持股9.65%),四足/人形机器人龙头,2026年科创板IPO过会,IPO估值420亿元。2.银河通用机器人美团天使轮领投、最大外部股东(持股15%),通用人形机器人Galbot落地药店自动分拣,估值210亿。3.普渡科技多轮大额参投,商用送餐机器人龙头,服务机器人赛道独角兽。4.星海图、自变量机器人美团联合/独家领投,专攻具身大模型(机器人大脑),单家估值破百亿,国内端到端通用机器人底座厂商。三、国产GPU/算力芯片AI独角兽1.摩尔线程国产桌面GPU龙头,美团早期投资,上市首日市值破3000亿。2.沐曦股份通用AI训练GPU独角兽,美团布局算力底层,对标英伟达A/H100。3.紫光展锐、爱芯元智AI边缘计算、车载芯片独角兽,美团布局终端AI算力。美团8年累计投资28家AI独角兽、43家硬科技企业,7家已完成上市。

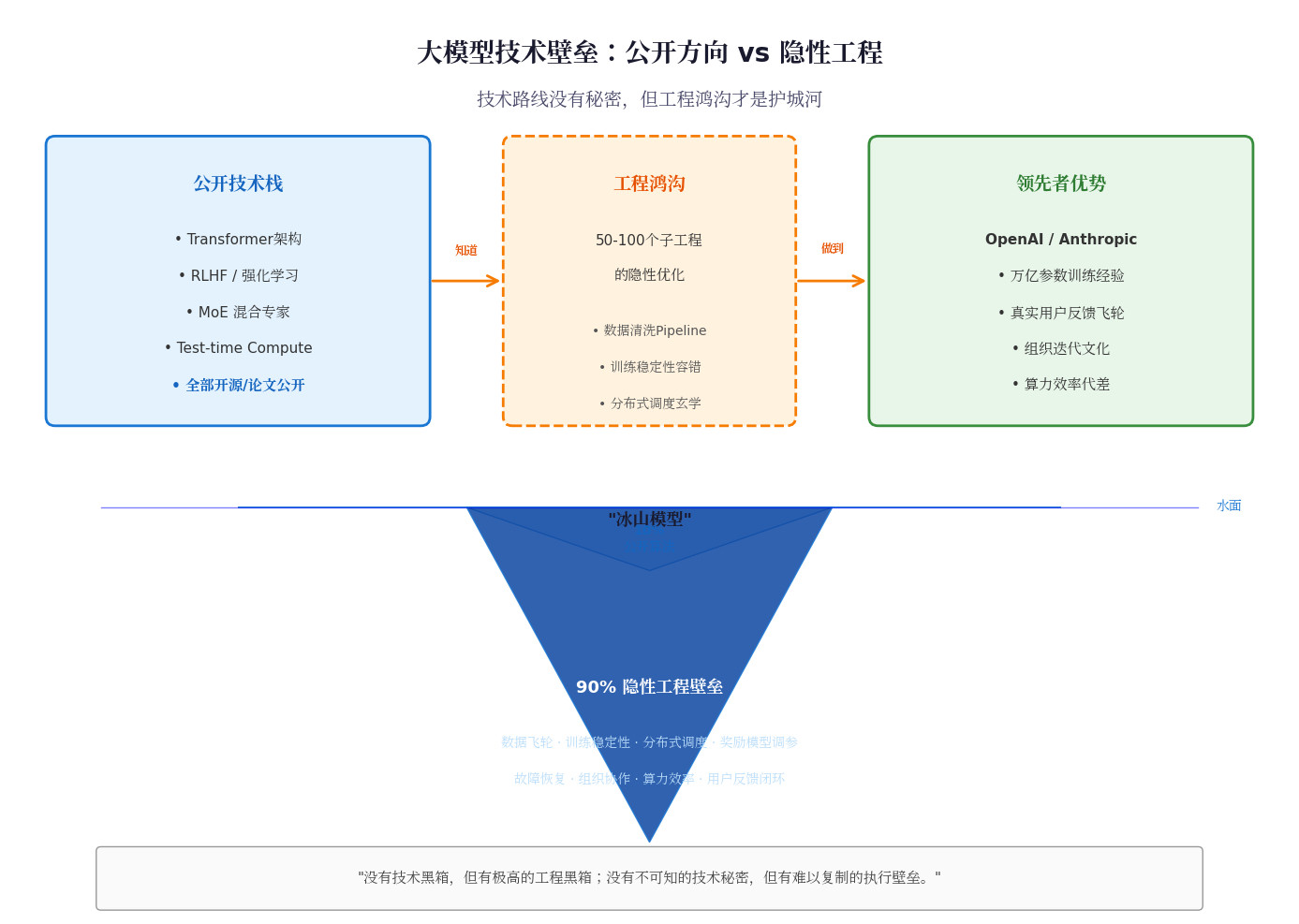
从龙芯到GPU!唐志敏54岁再创业,为何总挑最硬的骨头啃?当全网吹捧“芯片
从龙芯到GPU!唐志敏54岁再创业,为何总挑最硬的骨头啃?当全网吹捧“芯片英雄”时,谁看见唐志敏孤注一掷的狠劲?54岁本可退休,他却砸声誉、赌融资,在GPU赛道硬刚英伟达——这哪是创业?分明是拿命填中国芯片最后的窟窿!第一,他专挑“死局”破。从龙芯一号终结无芯史,到海光借x86弯道超车,再到现在象帝先死磕GPU,唐志敏每次都选最难的路。别人躲着国外技术封锁,他偏要正面刚:“总要有人做!”第二,人才是他唯一的赌本。甘当人梯培养团队,连下属报告都代写,换来百人死忠研发军团。融资崩盘时没人跑路,只因跟着他“把不可能变可能”。第三,54岁敢押上全部。对赌失败?裁员危机?老将偏要绝地重生。网友骂“疯子”,他却说:“国产芯片要好用,不是可用!”









GPU之间的数据传输增长呈指数级增长,这都涨到天上去了,全球AI光模块PCB市场
GPU之间的数据传输增长呈指数级增长,这都涨到天上去了,全球AI光模块PCB市场规模年增速的幅度高达83%,远远超过同期的光模块60%增速,而且,人工智能确实大动了,这些产业链的高速增长!AI人工智能是一个庞大的工程与基础建设相关产业链相对比较广泛!这些都是前期的需求增长!人工智能的基础建设,还属于一个初期发展阶段,等到下一个阶段,就是AI物理发展,也就是AI应用软件,让AI人工智能拥有自己的身体。到那个时候,那么产业链的集群就会更大!

这两年跟几个做金融AI的朋友聊天,发现一个挺普遍的现象:GPU采购预算批得爽快,
这两年跟几个做金融AI的朋友聊天,发现一个挺普遍的现象:GPU采购预算批得爽快,上架之后实际利用率却惨不忍睹。显卡经常在那儿"等着",数据从存储搬过来要时间,网络传过来要时间,等数据到了,计算早就跑完了——典型的"车等油"。金融智能体对这个问题的敏感度尤其高。实时反欺诈、动态授信、智能投顾,智能体要在毫秒级完成"感知-决策-执行"闭环。数据路径一拥堵,推理时延抖动,体验和风控效果一起打折。中科曙光这次在金融展上推的"元融"方案,说白了就是冲着"不让GPU空等"来的。算力是scaleX40超节点——单节点40张GPU,显存加起来5TB多,万亿参数模型能装下。存储是ParaStorF9000,单节点带宽220GB/s,能同时给40张卡各喂5GB/s以上的数据。网络是scaleFabric,端到端时延压到0.93微秒。三层拉通之后,数据不用再从存储"长途跋涉"去找算力,算力就贴着数据跑。"元融"专攻AI创新和智能体推理,当然也有FlashNexus9000专门守住核心交易。江海证券已经跑通了四大场景。大模型推理从秒级压到百毫秒级,这个提升在真实业务里体感还是挺明显的。中科曙光元融金融展


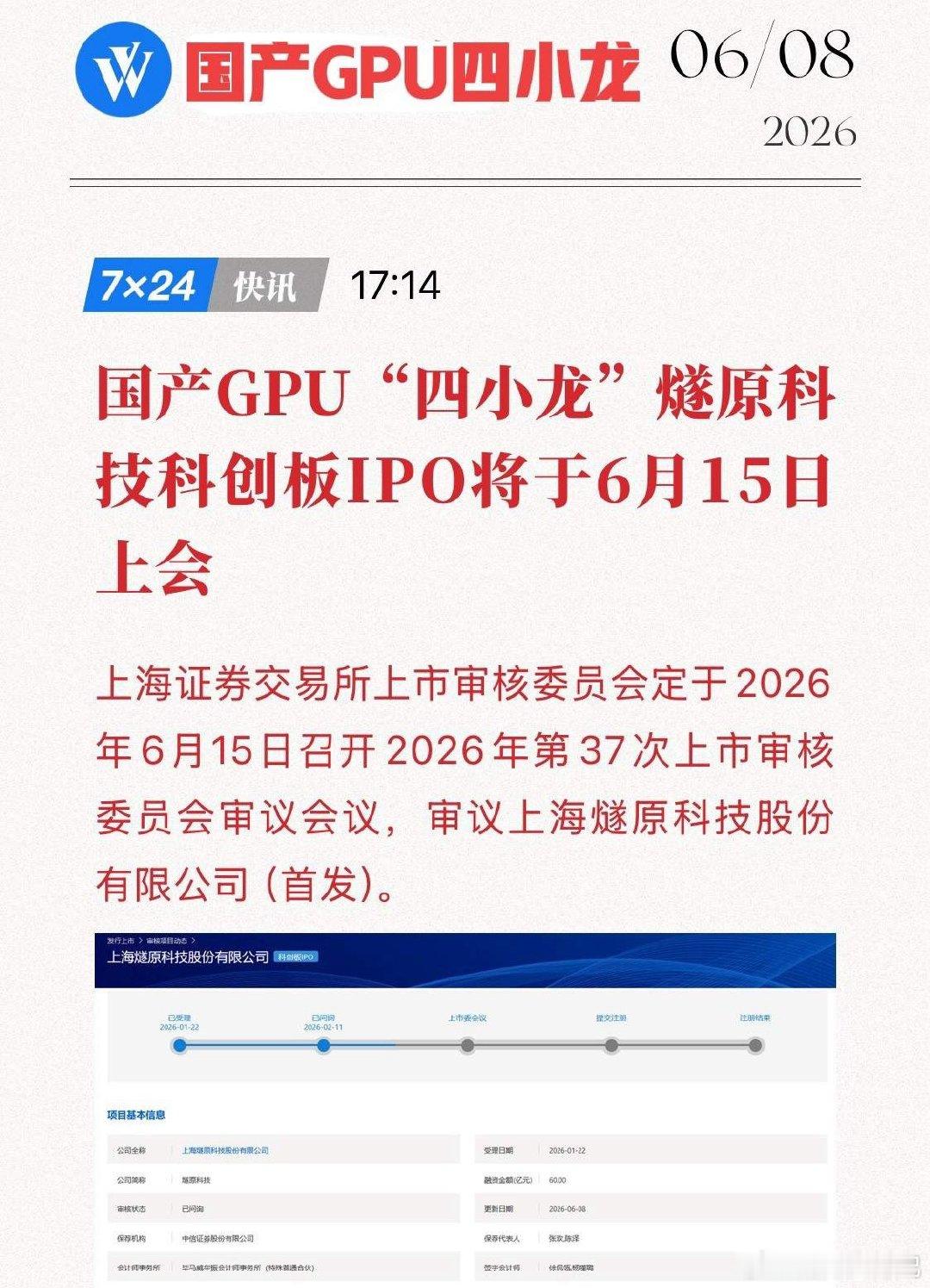
6月16日,五大短线热门板块!一、AI算力GPU半导体板块逻辑:燧原科技科创板I
6月16日,五大短线热门板块!一、AI算力GPU半导体板块逻辑:燧原科技科创板IPO过会,国产算力芯片加速替代寒武纪、海光信息、弘信电子、浪潮信息、紫光股份、中船特气、首都在线、兆易创新二、HVLP算力铜箔板块逻辑:头部厂商订单排至2027下半年,高端超薄铜箔供需缺口持续扩大铜冠铜箔、德福科技、隆扬电子、嘉元科技、诺德股份、超华科技、生益科技、台光电子三、高纯硅硅基量子芯片板块逻辑:攻克硅基量子芯片核心原料,同步利好高端半导体硅片国产自主沪硅产业、有研硅、有研新材、中核科技、兰石重装、杭氧股份、华特气体、中芯国际四、锂电储能板块逻辑:亿纬锂能预告2026半年净利大增95%-110%,锂电全产业链盈利修复亿纬锂能、宁德时代、比亚迪、天赐材料、恩捷股份、融捷股份、阳光电源、国轩高科五、6G卫星互联网超材料板块逻辑:我国超表面电磁调控核心样品研制落地,为6G毫米波、低轨卫星通信底层核心技术光启技术、中国卫星、航天电子、信维通信、国博电子、盛路通信、盟升电子、硕贝德个人观点,仅供参考!欢迎点赞关注,赠人玫瑰、手有余香,祝大家投资一路长虹!股市分析股市点评股票财经股票交流



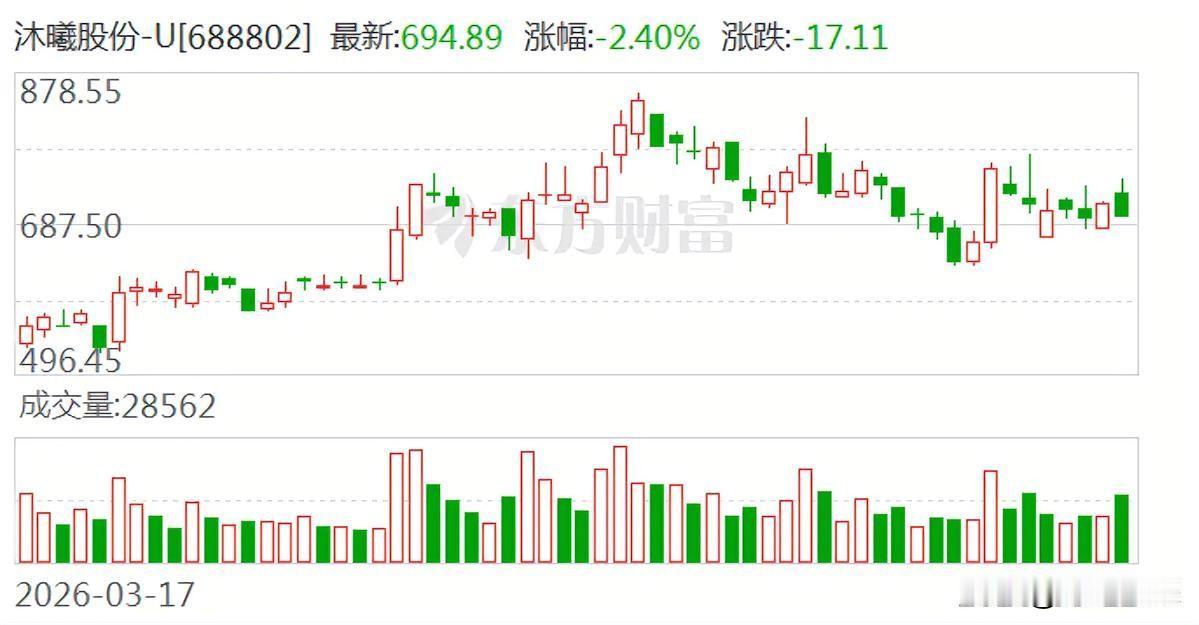
沐曦股份刚在科创板站稳脚跟,转身就直奔港交所。这家国产GPU独角兽的动作,刚
沐曦股份刚在科创板站稳脚跟,转身就直奔港交所。这家国产GPU独角兽的动作,刚好踩在AI算力由海外单一供给转向国产并存的节骨眼上,它的目的很明确,就是去拿国际资本,重注砸向下一代通用GPU和软件生态。对于还在高研发投入期、亏损收窄的沐曦来说,光靠A股显然不够解渴。搞通用GPU这事,烧钱周期长、生态壁垒高,不备足粮草很难跟得上。但还是不少人质疑,毕竟公司刚上市不久,理财还没焐热就又要融资,吃相有点难看。但这或许正是硬科技的残酷现实,不拼命砸钱迭代,技术就会掉队,想保持身位就得持续吸金。这种刚上市就再融资的激进打法,你觉得是长期主义还是急于圈钱?评论区聊聊。




AI会带来失业,也会带来更多就业机会!失业的人会拼命生存,这种生命力很强!正如当
AI会带来失业,也会带来更多就业机会!失业的人会拼命生存,这种生命力很强!正如当年直播干翻了线下零售,但也逼着更多零售商和工厂都招直播主播销售,极大的增加了就业!被迫创业潮大厂降本增效,首当其冲的是总监级中层。这批人有经验、有积蓄、有人脉,却被“逼上梁山”。不是想创业,是没得选。这种“被迫创业”与主动创业完全不同——主动创业是锦上添花,被动创业是背水一战。生存本能驱动的爆发力惊人,就像欧洲大航海:活不下去,才出海。今天的大厂裁员潮,本质上是在向全球输送一批最凶狠的创业者。00后创业者正在涌现00后的产品定义跟老一辈完全不在一个频道,天生就是AI原住民,认为AI工具就像水电一样自然。面对这种变化,VC的出手策略急剧调整——要么投极早期(1000-3000万人民币),要么投极后期,中间成长期几乎不碰。估值涨上来了,数据还没跑出来,竞品突然冒出好几个,根本没法判断谁能胜出。目前市场上形成了两套投资套路:1.完全市场化:产品好、技术领先、卖货赚钱2.国家战略:跟着政策走,投GPU、火箭、大模型、核聚变