全世界都以为 AI 的战场还在美国硅谷,居然有一个国家,悄无声息地把 AI 调用量干到了美国的 2.4 倍,全球科技圈愣是没一个人提前反应过来,世上居然还有如此魔幻的事?
观察者网 5 月 6 号爆出猛料,根据全球最大 AI 模型 API 聚合平台 OpenRouter 最新数据,4 月 27 日至 5 月 3 日这一周,中国大模型周调用量暴涨 81.7%,直接冲到了 7.94 万亿 Token,而同期美国仅为 3.26 万亿 Token。
前十名的榜单上,前两名全是中国的。腾讯 Hy3 preview 免费版以 3.03 万亿 Token 的周调用量登顶,环比暴涨 799%;亚军的是 Kimi K2.6,1.28 万亿 Token;长期霸榜的 Claude Sonnet 4.6 被挤到第三,也就是 1.35 万亿 Token,环比还跌了 1%。
刚上架不到半个月的 DeepSeek-V4-Flash 首次露面就杀进第九,周调用量飙升 344%。
这不仅仅是赢了。这是对所谓“算力决定一切”论调的一次现场打脸。
为什么选 OpenRouter 的数据?因为这家成立于 2023 年的公司是全球最大的 AI 聚合平台,整合了 GPT-4、Claude、DeepSeek、Qwen 等 400 多个模型,拥有超过 500 万开发者用户。
更重要的是,在这个平台上,有将近一半的用户来自美国,只有不到 10% 来自中国。
也就是说,这些“投票”绝大多数是美国乃至全球开发者自己投给中国模型的。
他们用自己的饭碗、自己的代码库、自己手头的真金白银,告诉硅谷的巨头们:谁便宜、谁好用、谁扛得住高强度调用,我们就用谁。资本永远比嘴诚实。
斯坦福大学今年 4 月发布的《2026 年 AI 指数报告》显示:中美顶级模型的性能差距已经缩小到 2.7%。
而且,报告直接用了四个字——“实质性消除”。
也就是说,性能没差多少,但中国模型价格却是美国对手的一个零头,甚至一个零头的零头。
你想,如果你是做应用的印度创业者、中东电商开发者,甚至是在硅谷公寓里刚起步的穷大学生,你选谁?
这下彻底颠覆了过去两年制约 AI 普及的最大瓶颈。
但我们得冷静看这个“7.94 万亿”——这个数字背后有一个隐情。
这个量并不是全球所有 AI 落地的全部,而是 OpenRouter 这一个平台上的数据。
但它依然有参考价值:全球开发者最高频、最活跃、最倚赖的生产力工具目前正在向中国富集。
甚至在 4 月第一周,两者的差距一度达到令人发指的 4.27 倍。
美国那一边是什么反应?一个字:熬。
从去年年底开始,美国那边海量资金全部砸在训练大模型上,单是 OpenAI 和 Anthropic 的两家最新旗舰训练成本就接近六位数万美元级。
但当他们终于做出号称“非常强大”的新版本时,发现调用量的增长趋势反而往下掉。
OpenRouter 的数据显示美国模型调用量环比下滑 34.6%,为几个月来的最大跌幅。
市场上最有价值的编程等高要求领域,虽然 Claude 仍霸占头部,但底层基础模型的需求正在被中国模型虹吸。
这就引出来第二个炸点。能走到今天这一步,不是纯粹靠运气或者降价。这是一个被逼到角落之后逼出来的生存哲学。很多人称之为“雕花哲学”。
从 2022 年美国对高端芯片封锁升级,到 2025 年 4 月禁止 H20 出口,再到 2026 年的法案禁止出口第七代 AI 加速卡,局面极其难看。
明面上英伟达偶尔被批准卖一池子边角料服务器,但交付后的审查政策相当严苛。
在这种背景下中国企业无法像硅谷那样躺在大规模 GPU 集群上暴力试错、野蛮迭代。
那怎么办?只能在算法架构、MoE 混合专家网络、训练细节上穷尽去磨,把能挖掘的每一丝潜在算力用到极致。
现在这个“被迫极限优化”的中国模型军团,正在全球商业市场上对暴力投入的硅谷大块头形成包围。
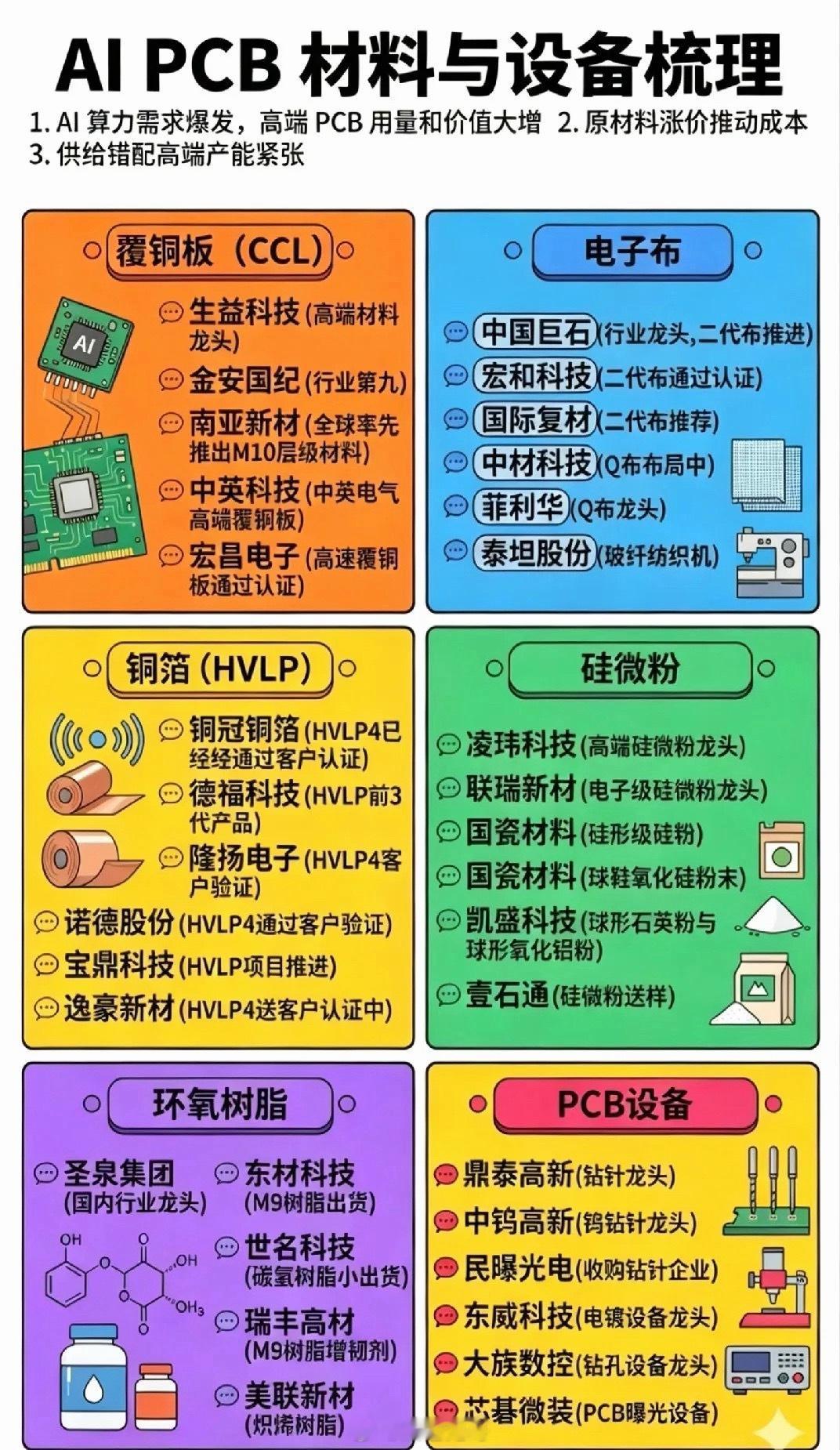
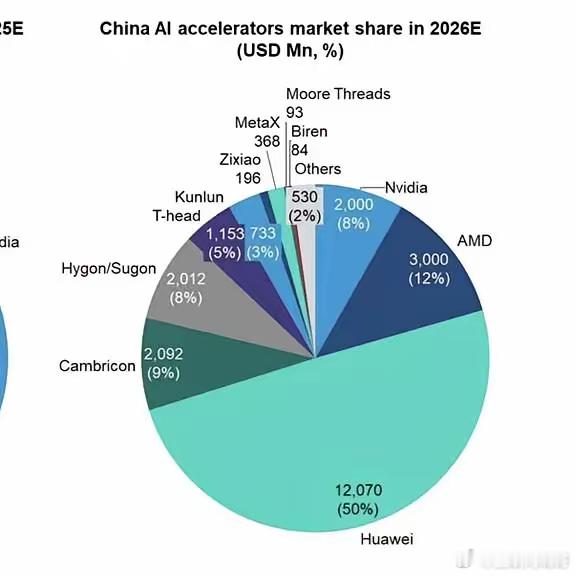
还有一个被人忽视的关键变量:硬件的国产替代已悄然进入质变阶段。
2025 年底到 2026 年初,华为昇腾、寒武纪及一系列新创 AI 芯片企业在“新型算力架构”上全面接力。
深度求索的 V4 系列甚至实现了对国产芯片架构建模的专项优化。
这些硬件在推理性能上相当能打,彻底避免了底层算力被锁死。
一张身份证件丢失就让整场灾难爆发的戏剧性故事或许不太适合这里,但算力链条悄然转向国内生产的战略意义,不需要任何比喻衬托。
但让人感到荒诞的还不是 2.4 倍的差距,而是一个如此剧烈的产业结构变化,在发生之前全球科技圈没人提前反应过来。