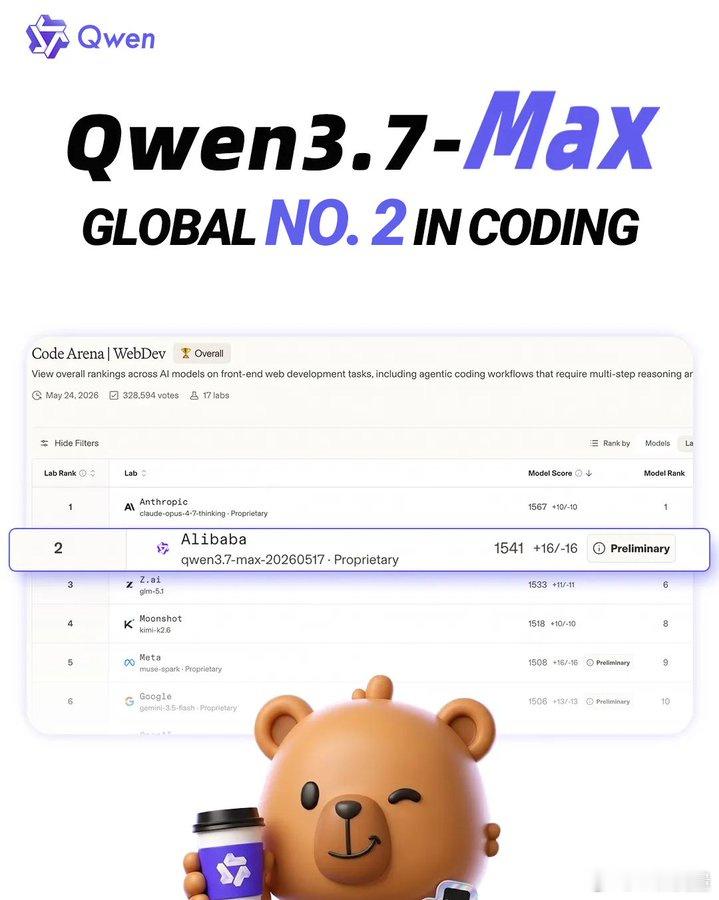
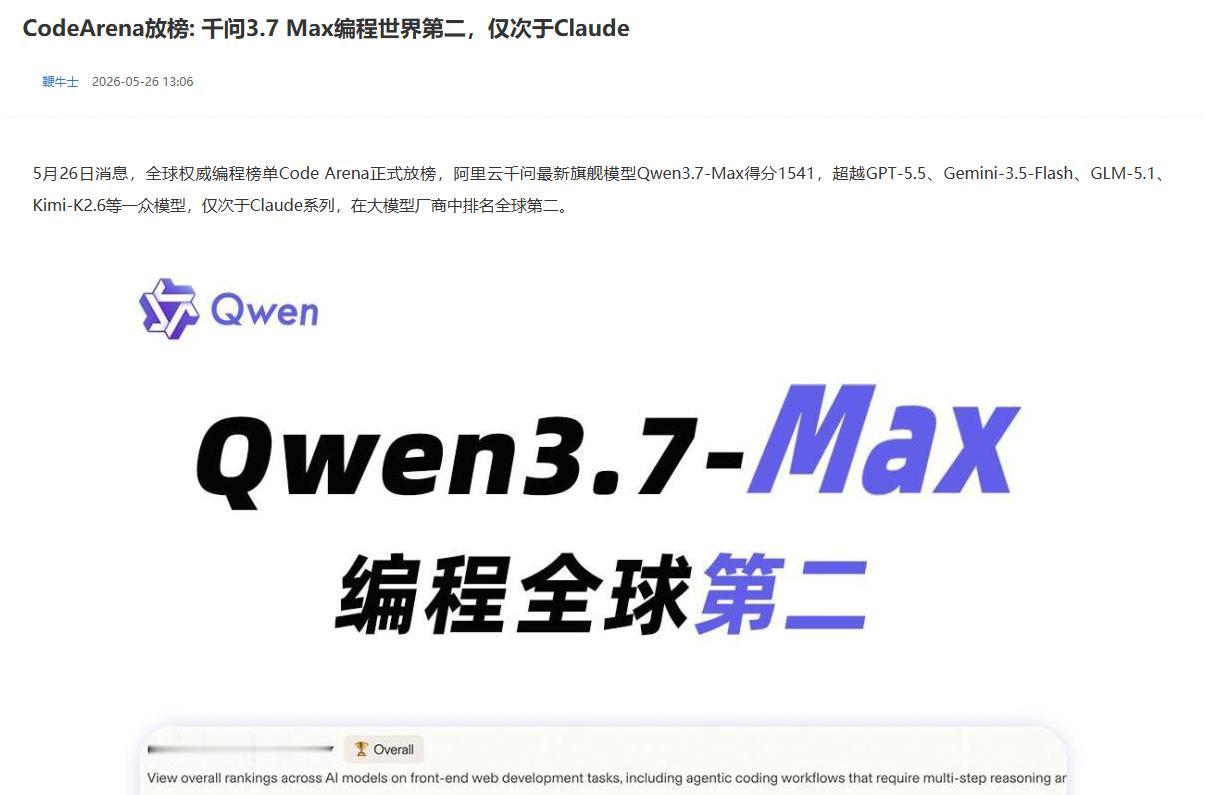
昨天凌晨,全球权威三方编程榜单 Code Arena 放榜,阿里巴巴的 Qwen3.7-Max 以 1541 分的成绩,在大模型厂商中排名全球第二,仅次于Claude 系列。
这是国产大模型在编程领域取得的最好成绩。
Code Arena 是什么?为什么这个榜单有含金量?
跟那些做选择题、填空地的学术化评测不同,Code Arena 评估的是模型在生成、调试、重构复杂代码时的实际编程能力。
简单来说,这个榜单测的不是"背书能力",而是"实战能力"。
在这个榜单上, Qwen3.7-Max 全球总排名第四,落后于 claude-opus-4-7-thinking 、claude-opus-4-7 、claude-opus-4-6-thinking ,但在大模型厂商中排名第二,仅次于Claude系列。
更值得关注的是,它超越了 Claude Opus 4.6 、GPT-5.5 、 Gemini-3.5-Flash 、GLM-5.1 、Kimi-K2.6 等一众前沿模型。
35小时任务、1158次工具调用:Qwen3.7-Max的" Agentic"能力
Qwen3.7-Max 真正让人眼前一亮的,是它在长时程 Agent 任务上的表现。
阿里巴巴在 5 月 20 日发布这个模型的时候,透露了一个很硬核的测试案例:
在从未接触过的全新芯片平台(平头哥真武M890 芯片)上,无任何性能分析数据、硬件文档或新架构示例内核的前提下, Qwen3.7-Max 从空白工作空间起步,自主完成了内核优化的全流程。
这个任务耗时 35 小时,期间累计完成1158次工具调用,同时进行了 432 次内核评估。最终,通过自主编程和超 1000 次工具调用,实现了关键内核的自我进化,推理速度较原版本提升 10 倍。
这个数字很惊人。 35 小时不间断工作、1000 多次工具调用、几百次评估迭代……
除了芯片内核优化这种硬核场景, Qwen3.7-Max 在企业级办公自动化场景也有显著突破。
在办公自动化基准 SpreadSheetBench-v1 上,Qwen3.7-Max 获得 87 分,处于顶尖水平。这个能力,对于很多企业来说,意味着生产关系的改变。
期待后续有更多优秀国模的发布