就在整个全球AI行业集体涨价的风口浪尖,中国大模型直接扔出了一颗王炸。
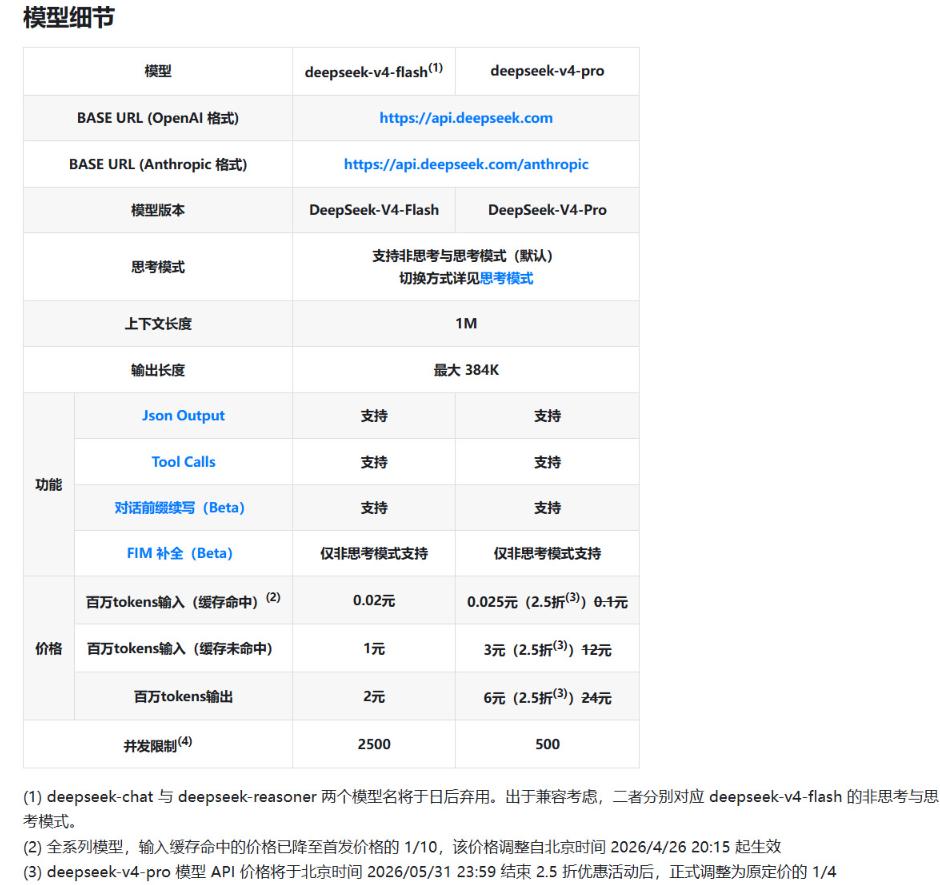
5月下旬,DeepSeek正式官宣,旗下旗舰级模型V4-Pro的API调用价格,永久降价75%。原本说好5月31日就结束的2.5折限时优惠,直接变成了永久定价,再也不回调了。
这个降价幅度有多夸张?调整之后,V4-Pro缓存命中的输入价格,低到了每百万Tokens只要0.025元人民币。
什么概念?你让AI处理一百万字的文本内容,成本才两分五厘钱。就算是没有命中缓存的全新输入,每百万字也才3块钱,输出内容每百万字6块钱。
横向对比一下海外的头部模型,差距瞬间就拉开了。
OpenAI最新的GPT-5.5,输出价格是30美元每百万Tokens,换算成人民币差不多216块。
Anthropic的Claude Opus4.7更贵,输出价格高达75美元每百万Tokens,差不多540块人民币。
也就是说,同样处理一百万汉字的输出内容,用海外旗舰模型要花几百块,用DeepSeek只要6块钱,成本差了几十上百倍。
也正是因为这个夸张的定价,全球知名AI评估机构Artificial Analysis最新的评测报告里,DeepSeek-V4-Pro直接登顶了全球大模型性价比排行榜的第一位。
在统一标准的压力测试里,完成一次完整的高端推理任务,它只需要268美元,成本只有GPT-5.5的十二分之一,Claude Opus4.7的十九分之一,这个优势可以说是碾压级的。
很多人第一反应可能会问,卖这么便宜,是不是性能缩水了?这还真不是。
这次降价完全是“加量不加价”,V4-Pro的性能没有任何妥协,依然保持着国际顶尖的水准。
尤其是在智能体协同、长文本处理和代码生成这些高端场景里,它的表现和海外旗舰模型的差距已经非常小,在中文场景下甚至还有优势。
最关键的是,这次降价真不是什么烧钱换市场的营销套路,也不是短期赔本赚吆喝。DeepSeek敢在全行业涨价的时候逆市降价,核心底气来自于实打实的技术突破,而不是资本补贴。
之前海外模型卖得贵,很大程度上是因为它们的架构效率不够高,还要依赖价格越来越贵的进口高端GPU,成本根本降不下来,只能跟着硬件涨价一起提价。
而DeepSeek走了一条完全不同的路。它自研了稀疏注意力机制和混合专家架构,把长文本处理的算力消耗直接降到了前代的27%,缓存占用的显存更是砍到了原来的10%。
简单说就是,同样的算力,它能处理的任务量是别人的好几倍,单位成本自然就下来了。
更重要的是,它已经深度适配了国产算力芯片,不用再被海外GPU的产能和价格卡脖子。
在此之前,高端大模型的定价权基本掌握在海外厂商手里,它们定多少钱,行业就跟着走。
中小企业和普通开发者想用顶级AI能力,就要承担极高的成本,很多创业团队光每个月的AI调用费就要几万甚至几十万,稍微调用量大一点,成本直接就扛不住了。
现在这个局面被彻底打破了。百万字两分五的价格,意味着AI调用的成本已经低到了几乎可以忽略不计的程度。
一个中小开发团队,之前用海外模型一个月要花五千块的调用费,现在可能一百块就够了。普通用户哪怕天天高强度用AI,一个月的成本可能还不到一杯奶茶钱。
这才是真正的AI普惠。之前很多人说AI会改变世界,但如果用一次就要几块钱,大部分人根本不敢放开用,那改变世界就只是一句空话。
当成本降到几乎为零的时候,AI才会真正像水电一样,变成人人都能用得起的基础工具,各种之前想都不敢想的应用才会真正爆发出来。
当然,这次降价也给整个行业出了一道难题。现在所有的大模型厂商都要面对一个灵魂拷问:如果你的模型性能不比DeepSeek强,价格还比它贵十几倍,那用户为什么还要选你?
可以预见的是,接下来整个大模型行业的定价体系都会被重构。之前那种“性能涨一点,价格翻几倍”的套路再也走不通了,行业竞争会从单纯的参数比拼,真正转向技术效率和成本控制的比拼。
而对于我们普通用户来说,这绝对是天大的好事。之前我们只能被动接受海外厂商的定价,现在有了国产模型的极致性价比,我们终于有了选择的底气。
更重要的是,这一次我们不再是跟在别人后面追赶,而是靠自己的技术和产业链,把全球高端AI的价格打了下来。
很多人总说中国AI只会模仿,只会打价格战。但这次的事实证明,我们不是靠偷工减料降价,而是靠架构创新和产业链优势,走出了一条自己的路。
当海外厂商还在靠稀缺性卖高价的时候,我们已经在用技术把高端AI变成普通人都用得起的普惠工具。
不是喊着要超越谁,而是踏踏实实把技术做好,把成本打下来,让每一个普通人都能享受到技术进步的红利。而这一次,我们确实站在了全球性价比的最顶端。