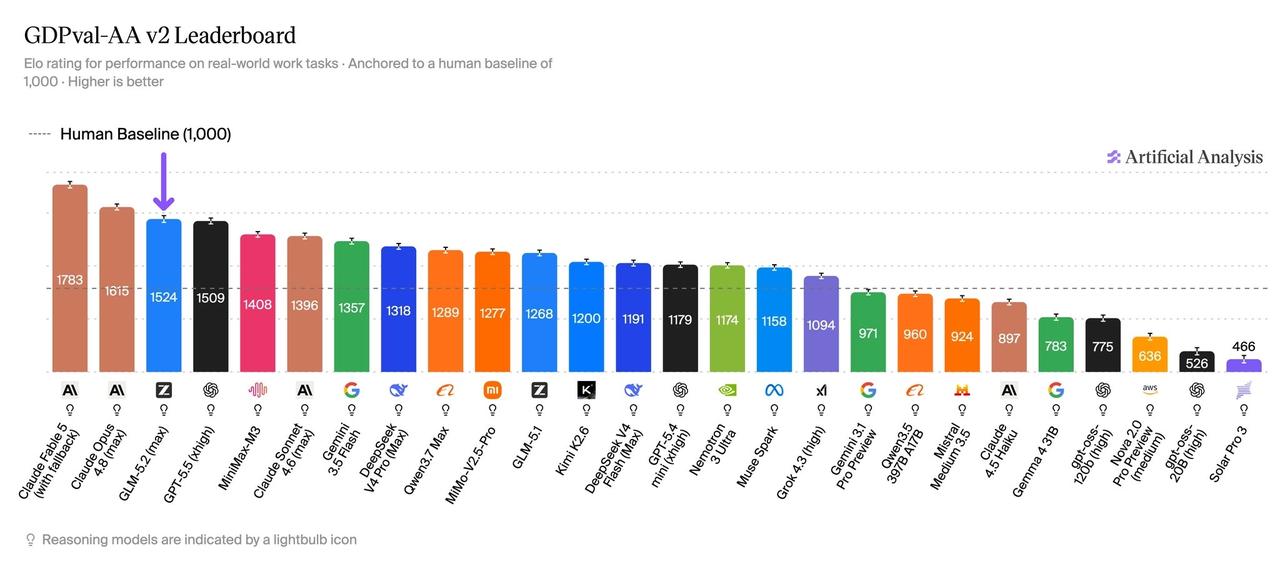
刚刚,GLM-5.2模型在权威基准测试 GDPval-AA中斩获了 1524 Elo 的高分,拿下全球第三。
这个基准专门用于评估模型在应对长时程、多轮对话等现实世界中具有实际价值的知识工作表现。
给你总结五个核心亮点:
1. 跻身全球前三:GLM-5.2 在总榜中高居第三位,表现与 GPT-5.5(xhigh,1509分)并驾齐驱,仅次于 Claude Fable 5(1783分)和 Claude Opus 4.8(1615分)。
2. 领跑开源生态:在开源权重模型中,GLM-5.2 具有明显的领先优势。紧随其后的开源模型 MiniMax-M3 得分为 1408 分,与其存在不小的差距。
3. 超越诸多主流商业模型:它的表现击败了众多知名的专有商业模型,包括谷歌的 Gemini 3.5 Flash(1357分)、通义千问 Qwen 3.7 Max(1289分)以及 Muse Spark(1158分)。
4. 强大的 Agent(智能体)能力:面对极具挑战性的 Agent 任务,GLM-5.2 在总计 1,999 场测试中,平均每项任务能高效应对约 31 轮的交互。
5. 全面领先的综合实力
除了在 GDPval-AA 表现亮眼外,GLM-5.2 在“人工智能分析指数”(Artificial Analysis Intelligence Index)的其他维度上也全面领跑开源模型。
其中在 **Agentic Index(智能体指数)** 和 **AA-Briefcase(公文包基准测试)** 中均位列全球第三。