Anthropic Fable 5(Mythos 5)跑分对比解读:IPO前模型实力对标GPT5.5
一、整体排位
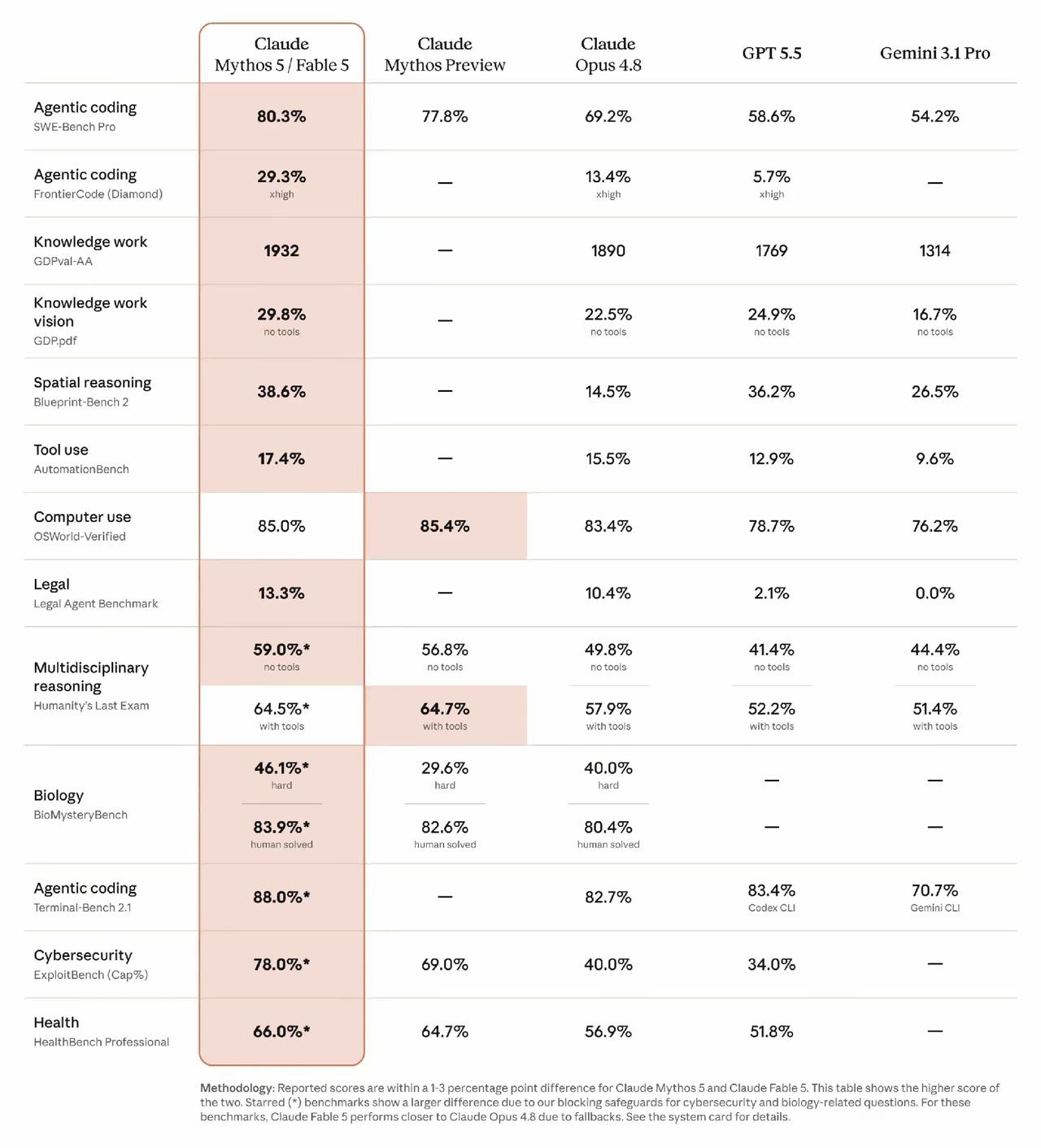
Claude Mythos 5/Fable 5是本次榜单综合第一,绝大多数基准测试分数超越GPT-5.5、Gemini 3.1 Pro、旧版Opus 4.8,是Anthropic冲刺IPO的核心技术筹码。
二、核心高分优势赛道
1. 智能体编码(Agentic coding)
SWE-Bench Pro拿到80.3%,大幅领先GPT5.5(58.6%)、Opus4.8(69.2%);Terminal-Bench 2.1达88%,代码智能体工程能力断层领跑,对应之前行业热议的AI自主写代码、调度工程任务能力。
2. 操作系统整机操作
OSWorld-Verified分数85%,和Mythos Preview几乎持平,高于GPT5.5(78.7%),AI操控电脑、执行系统指令的实操能力更强。
3. 安全攻防(网络安全)
ExploitBench达78%,GPT5.5仅34%,差距极大,在漏洞挖掘、安全攻防场景优势突出。
4. 专业领域能力
- 法律智能体:13.3%,GPT5.5仅2.1%,合规文书、法务流程推理优势明显;
- 医疗健康HealthBench:66%,高于GPT5.5的51.8%;
- 生物难题BioMystery:难题正确率46.1%,人工匹配解出率83.9%,生物科研场景适配更强。
5. 多学科综合推理
无工具模式59%,带工具模式64.5%,两项数值都高于GPT5.5、Gemini 3.1 Pro,复杂交叉问题思考深度更强。
三、小幅落后的少量场景
仅空间推理Blueprint-Bench2(38.6%)略低于GPT5.5(36.2%小幅领先差距不大);工具自动化Bench(17.4%)小幅高于竞品,不存在明显短板。
四、竞品对照
1. 旧版自家Opus 4.8:全维度被Fable 5拉开差距,编码、安全、生物、法律差距最明显;
2. GPT-5.5:仅空间推理微小领先,其余专业、Agent实操、安全、医疗、法律全线落后;
3. Gemini3.1 Pro:整体垫底,各类专业Agent场景分数差距显著。
五、IPO背后的商业意义
1. 技术背书:用顶尖跑分证明自研模型壁垒,抬升公司估值,对标OpenAI融资体量;
2. 企业市场抓手:更强的Agent编码、系统操控、法务医疗能力,更容易拿下政企、科研、安全行业大单;
3. 差异化路线:避开纯对话内卷,主打工程智能体、专业垂直场景,和通用聊天模型形成区分。
小补充
标注*代表安全屏蔽机制带来小幅分数波动,生物、安全类题型有防护兜底,实际可用能力依旧优于竞品;Fable5和Mythos5性能差值仅1-3个百分点,取二者最高分作为对外展示成绩。
AI测评体系 GPT-5.5 openai5 GPT5.6 Opus5.5 UE5模型 DLSS4.5