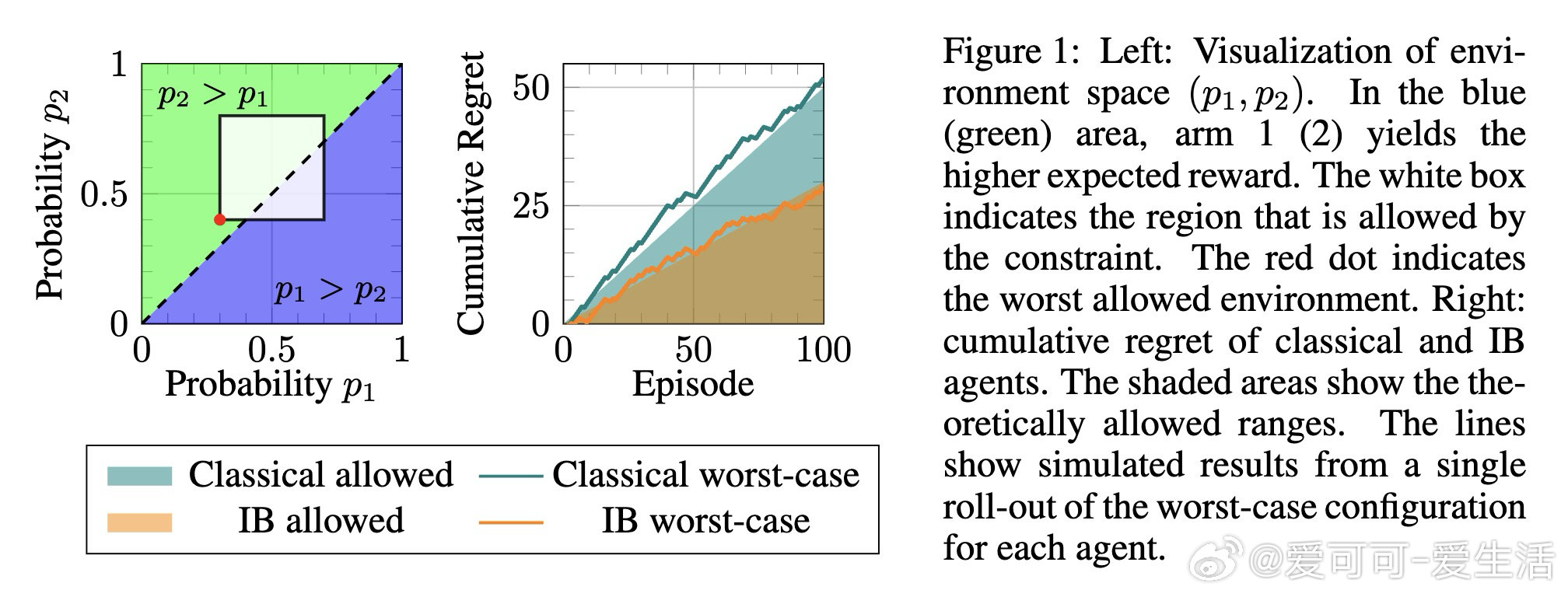
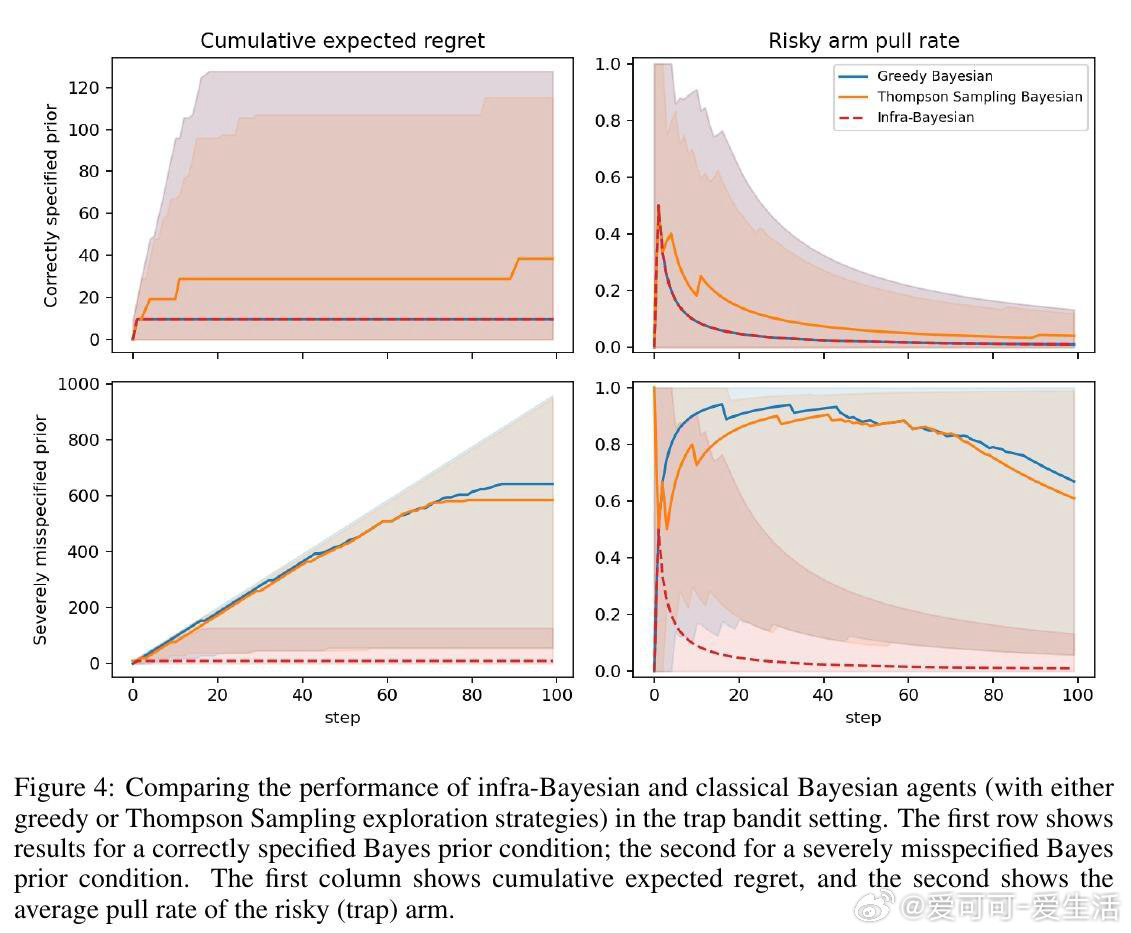
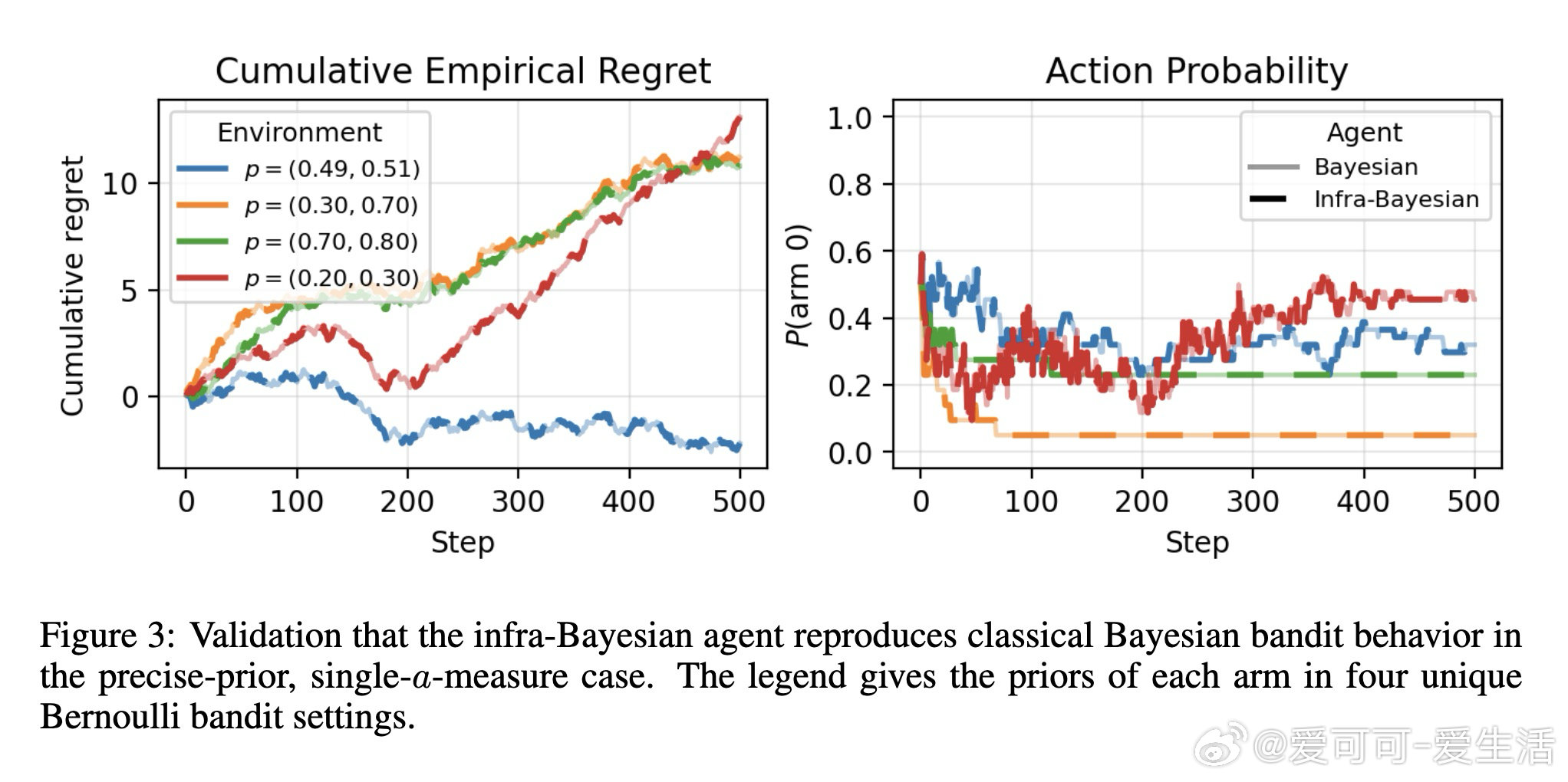
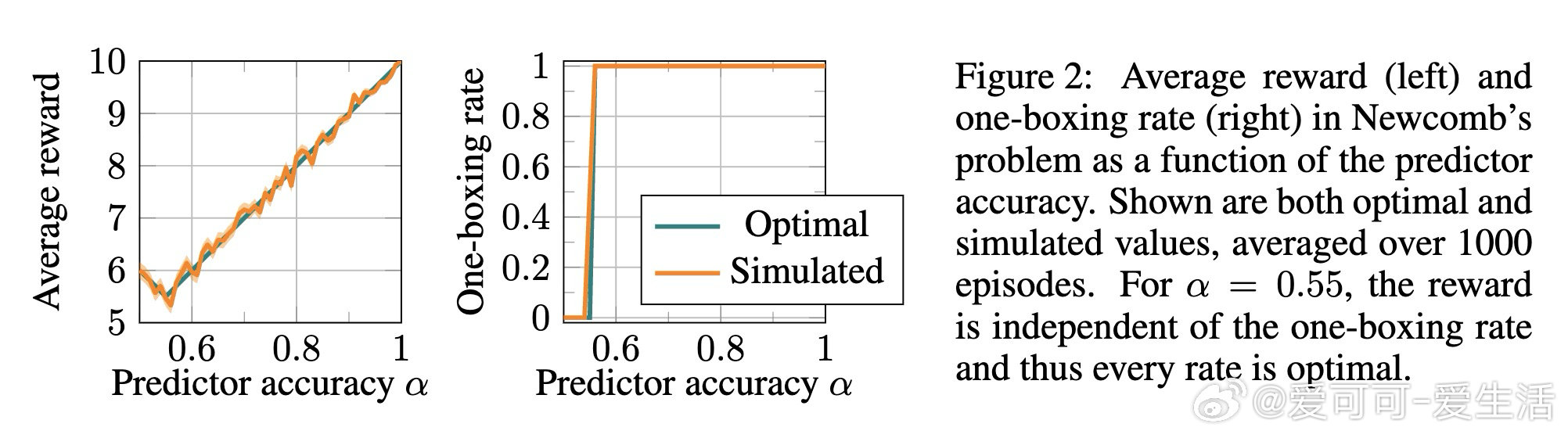
[LG]《Infra-Bayesian Reinforcement Learning Agents Outperform Classical RL For Worst-Case Robustness》M Aryal, F Azam, A Banerjee, S S M Jayanthi… [Purdue University & CMU & WorldQuant University] (2026)
在强化学习领域,固定环境假设难覆盖会预判智能体的世界。贝叶斯RL受困于可实现性假设,一旦模型类漏掉真实环境,后验会自信地错。
本文的核心洞见是:把不确定性重新分成概率不确定与Knightian不确定。由此,用下期望评估最坏可 admissible 环境,让策略优化转向保底收益。
这项工作留下的遗产是把infra-Bayesian理论做成可运行RL原型。它打开的新门是面向错设与策略依赖环境的鲁棒智能体;门槛是仍限于有限、无状态、小假设空间。
arxiv.org/abs/2605.23146 机器学习 人工智能 论文 AI创造营